Assignment : Supervised Learning


Section 1: Multiple Choice Questions
- Q1. You are building a supervised learning model to predict house prices. You have a dataset with features like square footage, number of bedrooms, and location, along with actual sale prices. Which statement best describes why this is a supervised learning problem?
- The model learns patterns without any labeled output data
- The dataset contains both input features and known target values for training
- The algorithm groups similar houses together based on their features
- The model generates new house price data based on existing patterns
- Q2. A classification model trained on customer data achieves 95% accuracy on the training set but only 65% accuracy on the test set. What is the most likely explanation for this behavior?
- The model has too few features to learn meaningful patterns
- The training dataset is too small to represent the problem
- The model has overfit to the training data and fails to generalize
- The test set contains different classes than the training set
- Q3. You need to choose between a regression and classification algorithm for a new project. Your target variable represents customer satisfaction scores ranging from 1 to 100. Which approach would be most appropriate and why?
- Classification, because the scores can be grouped into satisfaction categories
- Regression, because the target variable is continuous and numeric
- Classification, because there are exactly 100 possible output values
- Regression, because it handles categorical data better than classification
- Q4. When splitting a dataset into training and test sets, you decide to use 80% for training and 20% for testing. Why is it critical that the test set is never used during the model training process?
- To reduce computational time and memory requirements during training
- To ensure the model learns from a diverse range of examples
- To obtain an unbiased estimate of the model's performance on unseen data
- To prevent the training set from becoming contaminated with test data
- Q5. You are comparing two classification models: Model A has high precision but low recall, while Model B has high recall but low precision. In a medical diagnosis application where missing a disease (false negative) is more dangerous than a false alarm (false positive), which model should you prefer?
- Model A, because high precision minimizes incorrect diagnoses
- Model B, because high recall ensures fewer cases are missed
- Model A, because precision is always more important than recall
- Model B, because it will have higher overall accuracy
Section 2: Conceptual Questions
- Q1. Explain the fundamental difference between supervised and unsupervised learning. Provide one real-world example of each and justify why each example fits its respective category.
- Q2. What is the purpose of splitting data into training, validation, and test sets in supervised learning? Describe the specific role each set plays in the model development process.
- Q3. Define overfitting and underfitting in the context of supervised learning. What are the typical causes of each, and how can you identify them when evaluating your model?
Section 3: Code Tracing / Output Prediction
Code Snippet 1:
from sklearn.model_selection import train_test_split from sklearn.datasets import make_classification import numpy as np X, y = make_classification(n_samples=100, n_features=4, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) print("Training set size:", X_train.shape[0]) print("Test set size:", X_test.shape[0]) print("Number of features:", X_train.shape[1]) print("Unique classes:", np.unique(y))
Task: Predict the output of this code snippet and explain what each line does in the context of preparing data for supervised learning.
Code Snippet 2:
from sklearn.linear_model import LogisticRegression from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split X, y = make_classification(n_samples=200, n_features=5, n_informative=3, n_redundant=2, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42) model = LogisticRegression(random_state=42) model.fit(X_train, y_train) train_score = model.score(X_train, y_train) test_score = model.score(X_test, y_test) print("Training accuracy:", round(train_score, 3)) print("Test accuracy:", round(test_score, 3)) print("Number of training samples:", len(X_train))
Task: Explain what this code does step by step. What would it indicate if the training accuracy was 0.99 but the test accuracy was 0.65? What action would you take?
Section 4: Coding Problems
- Q1. Create a simple supervised learning workflow using Scikit-Learn to classify iris flowers.
- Load the Iris dataset using sklearn.datasets.load_iris()
- Split the data into 70% training and 30% testing sets
- Train a Logistic Regression classifier on the training data
- Print both training and testing accuracy scores
- Make predictions on the first 5 samples of the test set and print them
Sample Output:
Training Accuracy: 0.971 Testing Accuracy: 0.978 Predictions for first 5 test samples: [1 0 2 1 1] - Q2. Write a Python program that performs the following regression task:
- Generate a synthetic regression dataset with 150 samples and 1 feature using make_regression from sklearn.datasets
- Add some noise to the data (noise parameter = 20)
- Split into 80% training and 20% testing
- Train a Linear Regression model
- Calculate and print the R² score for both training and test sets
- Use random_state=42 for reproducibility
Expected Output Format:
Training R² Score: 0.xxx Testing R² Score: 0.xxx - Q3. Build a classification pipeline that demonstrates the importance of data splitting:
- Load the breast cancer dataset using load_breast_cancer() from sklearn.datasets
- Create three different train-test splits: 50-50, 70-30, and 90-10
- For each split, train a Logistic Regression model and record test accuracy
- Print a comparison showing how test set size affects the reliability of performance estimates
- Use random_state=42 for all splits
Sample Output:
Split 50-50: Test Accuracy = 0.xxx, Test Samples = xxx Split 70-30: Test Accuracy = 0.xxx, Test Samples = xxx Split 90-10: Test Accuracy = 0.xxx, Test Samples = xxx - Q4. Create a program that demonstrates overfitting versus proper fitting:
- Generate a classification dataset with 100 samples, 20 features, but only 2 informative features
- Split into 60% training and 40% testing
- Train two Logistic Regression models: one with default parameters and one with C=0.01 (stronger regularization)
- For each model, print training accuracy and testing accuracy
- Compare which model generalizes better
Input/Output:
Model 1 (Default) - Train: 0.xxx, Test: 0.xxx Model 2 (C=0.01) - Train: 0.xxx, Test: 0.xxx
Section 5: Challenge Problem (Optional)
Advanced Multi-Model Comparison Framework
Build a comprehensive supervised learning comparison system that:
- Loads the digits dataset (hand-written digit classification) using load_digits()
- Implements stratified train-test split (80-20) to maintain class distribution
- Trains three different classifiers: Logistic Regression, Decision Tree, and K-Nearest Neighbors
- For each classifier, calculates: training accuracy, testing accuracy, and the difference between them
- Creates a summary table showing all metrics for comparison
- Identifies which model has the best generalization (smallest gap between train and test accuracy)
- Uses cross-validation (5 folds) on the best model and reports mean cross-validation score
Constraints:
- Use random_state=42 throughout
- For KNN, use n_neighbors=5
- For Decision Tree, use max_depth=10
- Round all scores to 4 decimal places
- Print results in a clearly formatted table structure
Expected Output Structure:
Model Performance Comparison: ================================ Model: Logistic Regression Training Accuracy: 0.xxxx Testing Accuracy: 0.xxxx Difference: 0.xxxx Model: Decision Tree Training Accuracy: 0.xxxx Testing Accuracy: 0.xxxx Difference: 0.xxxx Model: K-Nearest Neighbors Training Accuracy: 0.xxxx Testing Accuracy: 0.xxxx Difference: 0.xxxx Best Generalizing Model: [Model Name] Cross-Validation Score (5-fold): 0.xxxx
Answer Key
Section 1 - MCQ Answers
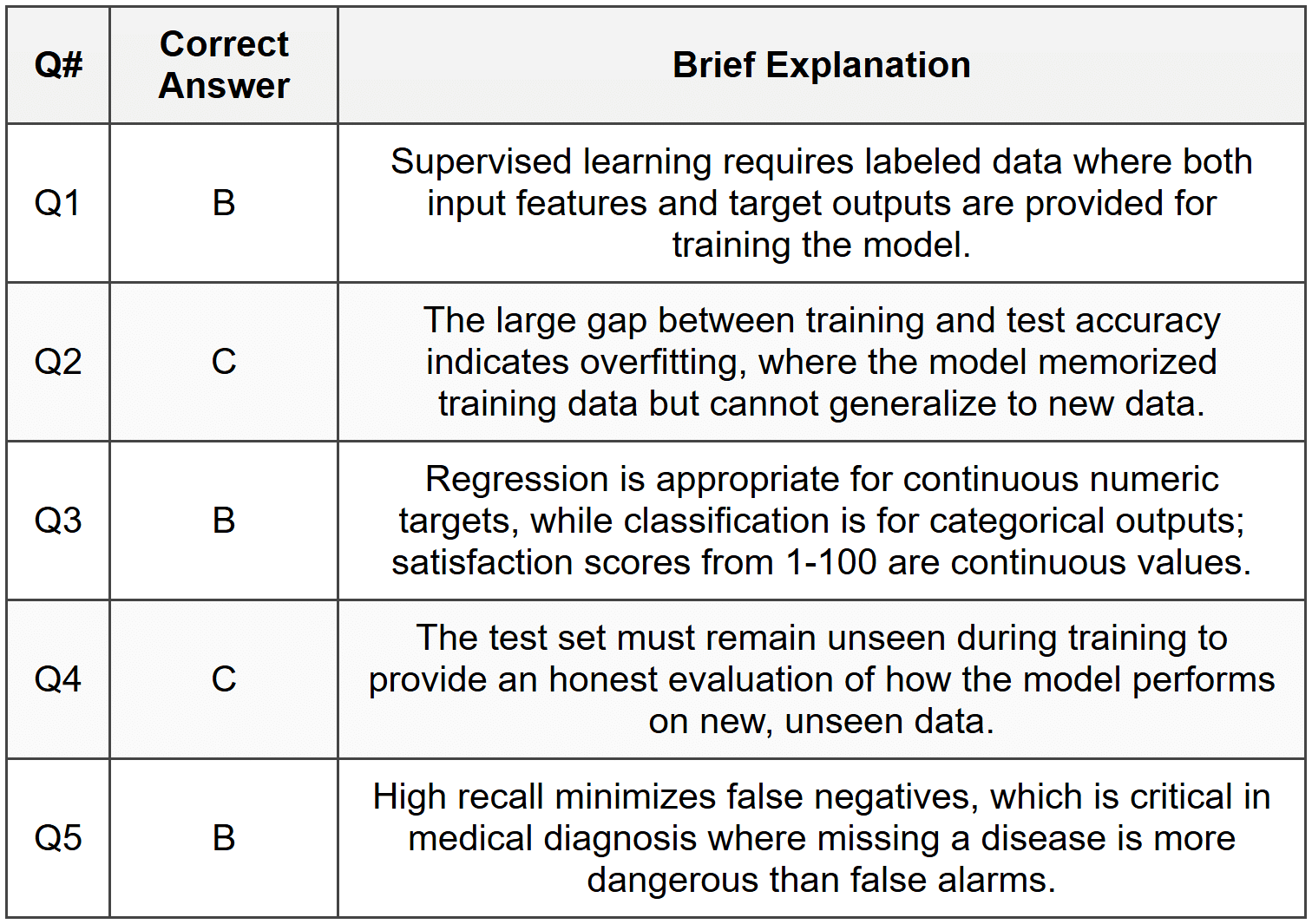
Section 2 Answers
Q1: Supervised learning uses labeled data where both input features and target outputs are provided, allowing the model to learn the mapping between them. Example: Email spam detection where emails are labeled as spam or not spam. Unsupervised learning works with unlabeled data to discover hidden patterns or structures. Example: Customer segmentation where customers are grouped based on purchasing behavior without predefined categories. The key difference is the presence or absence of labeled target values during training.
Q2: The training set is used to fit the model and learn patterns from the data. The validation set is used during model development to tune hyperparameters and make decisions about model architecture without touching the test set. The test set provides a final, unbiased evaluation of the model's performance on completely unseen data. This separation prevents data leakage and ensures honest assessment of generalization ability.
Q3: Overfitting occurs when a model learns the training data too well, including noise and random fluctuations, resulting in poor performance on new data. It is caused by model complexity being too high relative to the amount of training data. Underfitting occurs when a model is too simple to capture the underlying patterns in the data, performing poorly on both training and test sets. You can identify overfitting when training accuracy is very high but test accuracy is significantly lower, and underfitting when both training and test accuracies are low.
Section 3 Answers
Code Snippet 1 Output:
Training set size: 70 Test set size: 30 Number of features: 4 Unique classes: [0 1]
Explanation:
Line 1-2: Import necessary functions and create a synthetic binary classification dataset with 100 samples and 4 features.
Line 3: Split the data using 30% for testing (test_size=0.3), resulting in 70 training samples and 30 test samples.
Lines 4-7: Print the sizes of the resulting datasets and confirm there are 4 features and 2 classes (0 and 1).
The random_state parameter ensures reproducible splits.
Code Snippet 2 Output:
Training accuracy: (approximately 0.92-0.95) Test accuracy: (approximately 0.88-0.94) Number of training samples: 150
Explanation:
This code creates a synthetic classification dataset with 200 samples and 5 features (3 informative, 2 redundant).
It splits the data into 75% training (150 samples) and 25% testing (50 samples).
A Logistic Regression model is instantiated and trained on the training data.
The score() method calculates classification accuracy on both sets.
If training accuracy was 0.99 and test accuracy was 0.65, this would indicate severe overfitting. The model has memorized the training data but cannot generalize. Actions to take would include: adding regularization, reducing model complexity, gathering more training data, or using cross-validation to better tune hyperparameters.
Section 4 Answers
Q1 Solution:
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression # Load the Iris dataset iris = load_iris() X, y = iris.data, iris.target # Split into 70% training and 30% testing X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # Train Logistic Regression classifier model = LogisticRegression(max_iter=200, random_state=42) model.fit(X_train, y_train) # Print accuracy scores train_acc = model.score(X_train, y_train) test_acc = model.score(X_test, y_test) print(f"Training Accuracy: {train_acc:.3f}") print(f"Testing Accuracy: {test_acc:.3f}") # Make predictions on first 5 test samples predictions = model.predict(X_test[:5]) print(f"Predictions for first 5 test samples: {predictions}")
Approach: This solution loads the classic Iris dataset, splits it using train_test_split with the specified ratio, trains a Logistic Regression model, and evaluates performance. The max_iter parameter is increased to ensure convergence.
Q2 Solution:
from sklearn.datasets import make_regression from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression # Generate synthetic regression dataset X, y = make_regression(n_samples=150, n_features=1, noise=20, random_state=42) # Split into 80% training and 20% testing X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Train Linear Regression model model = LinearRegression() model.fit(X_train, y_train) # Calculate R² scores train_r2 = model.score(X_train, y_train) test_r2 = model.score(X_test, y_test) print(f"Training R² Score: {train_r2:.3f}") print(f"Testing R² Score: {test_r2:.3f}")
Approach: Creates a synthetic regression dataset with specified noise level, splits the data, trains a simple linear regression model, and evaluates using R² score which measures the proportion of variance explained by the model.
Q3 Solution:
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression # Load breast cancer dataset data = load_breast_cancer() X, y = data.data, data.target # Define split ratios splits = [(0.5, '50-50'), (0.3, '70-30'), (0.1, '90-10')] # Train and evaluate for each split for test_size, label in splits: X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=test_size, random_state=42 ) model = LogisticRegression(max_iter=10000, random_state=42) model.fit(X_train, y_train) test_acc = model.score(X_test, y_test) test_samples = len(X_test) print(f"Split {label}: Test Accuracy = {test_acc:.3f}, Test Samples = {test_samples}")
Approach: This solution demonstrates how different train-test splits affect evaluation. Larger test sets provide more reliable performance estimates but leave less data for training. The loop iterates through different split ratios for comparison.
Q4 Solution:
from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression # Generate dataset with many features but few informative ones X, y = make_classification( n_samples=100, n_features=20, n_informative=2, n_redundant=18, random_state=42 ) # Split data X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.4, random_state=42 ) # Model 1: Default parameters model1 = LogisticRegression(max_iter=10000, random_state=42) model1.fit(X_train, y_train) train_acc1 = model1.score(X_train, y_train) test_acc1 = model1.score(X_test, y_test) # Model 2: Stronger regularization model2 = LogisticRegression(C=0.01, max_iter=10000, random_state=42) model2.fit(X_train, y_train) train_acc2 = model2.score(X_train, y_train) test_acc2 = model2.score(X_test, y_test) print(f"Model 1 (Default) - Train: {train_acc1:.3f}, Test: {test_acc1:.3f}") print(f"Model 2 (C=0.01) - Train: {train_acc2:.3f}, Test: {test_acc2:.3f}") # Determine which generalizes better gap1 = train_acc1 - test_acc1 gap2 = train_acc2 - test_acc2 better_model = "Model 2" if gap2 < gap1="" else="" "model="" 1"="" print(f"{better_model}="" generalizes="" better="" (smaller="" train-test="" gap)")="">
Approach: Creates a scenario prone to overfitting with many features but few informative ones. Compares a default model against one with stronger regularization (lower C value). The model with smaller gap between training and test accuracy generalizes better.
Section 5 Answer
from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split, cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier import numpy as np # Load digits dataset digits = load_digits() X, y = digits.data, digits.target # Stratified train-test split X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y ) # Define models models = { 'Logistic Regression': LogisticRegression(max_iter=10000, random_state=42), 'Decision Tree': DecisionTreeClassifier(max_depth=10, random_state=42), 'K-Nearest Neighbors': KNeighborsClassifier(n_neighbors=5) } # Store results results = {} print("Model Performance Comparison:") print("=" * 32) # Train and evaluate each model for name, model in models.items(): model.fit(X_train, y_train) train_acc = model.score(X_train, y_train) test_acc = model.score(X_test, y_test) difference = train_acc - test_acc results[name] = { 'train': train_acc, 'test': test_acc, 'diff': difference } print(f"\nModel: {name}") print(f" Training Accuracy: {train_acc:.4f}") print(f" Testing Accuracy: {test_acc:.4f}") print(f" Difference: {difference:.4f}") # Find best generalizing model (smallest difference) best_model_name = min(results, key=lambda x: results[x]['diff']) best_model = models[best_model_name] print(f"\nBest Generalizing Model: {best_model_name}") # Perform cross-validation on best model cv_scores = cross_val_score(best_model, X_train, y_train, cv=5) mean_cv_score = np.mean(cv_scores) print(f"Cross-Validation Score (5-fold): {mean_cv_score:.4f}")
Explanation: This comprehensive solution loads the digits dataset and creates a stratified split to maintain class distribution across train and test sets. It trains three different classifiers and compares their performance metrics. The model with the smallest gap between training and testing accuracy is identified as having the best generalization. Finally, 5-fold cross-validation is performed on the best model to get a more robust estimate of its performance. Stratified splitting and cross-validation are important techniques for reliable model evaluation, especially with imbalanced datasets.



