









All Exams >
Computer Science Engineering (CSE) >
Algorithms >
All Questions
All questions of Greedy Techniques for Computer Science Engineering (CSE) Exam
Suppose the letters a, b, c, d, e, f have probabilities 1/2, 1/4, 1/8, 1/16, 1/32, 1/32 respectively. Which of the following is the Huffman code for the letter a, b, c, d, e, f?- a)0, 10, 110, 1110, 11110, 11111
- b)11, 10, 011, 010, 001, 000
- c)11, 10, 01, 001, 0001, 0000
- d)110, 100, 010, 000, 001, 111
Correct answer is option 'A'. Can you explain this answer?
Suppose the letters a, b, c, d, e, f have probabilities 1/2, 1/4, 1/8, 1/16, 1/32, 1/32 respectively. Which of the following is the Huffman code for the letter a, b, c, d, e, f?
a)
0, 10, 110, 1110, 11110, 11111
b)
11, 10, 011, 010, 001, 000
c)
11, 10, 01, 001, 0001, 0000
d)
110, 100, 010, 000, 001, 111
|
|
Sanya Agarwal answered |
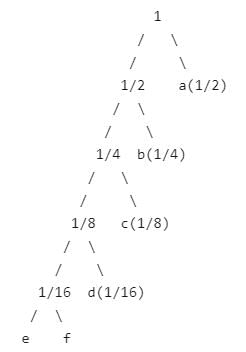
We get the following Huffman Tree after applying Huffman Coding Algorithm. The idea is to keep the least probable characters as low as possible by picking them first.
The letters a, b, c, d, e, f have probabilities
1/2, 1/4, 1/8, 1/16, 1/32, 1/32 respectively.
1/2, 1/4, 1/8, 1/16, 1/32, 1/32 respectively.

A networking company uses a compression technique to encode the message before transmitting over the network. Suppose the message contains the following characters with their frequency: Note : Each character in input message takes 1 byte. If the compression technique used is Huffman Coding, how many bits will be saved in the message?
Note : Each character in input message takes 1 byte. If the compression technique used is Huffman Coding, how many bits will be saved in the message?- a)224
- b)800
- c)576
- d)324
Correct answer is option 'C'. Can you explain this answer?
A networking company uses a compression technique to encode the message before transmitting over the network. Suppose the message contains the following characters with their frequency:
Note : Each character in input message takes 1 byte. If the compression technique used is Huffman Coding, how many bits will be saved in the message?
a)
224
b)
800
c)
576
d)
324

|
Crack Gate answered |
Total number of characters in the message = 100.
Each character takes 1 byte. So total number of bits needed = 800.
Each character takes 1 byte. So total number of bits needed = 800.
After Huffman Coding, the characters can be represented with:
f: 0
c: 100
d: 101
a: 1100
b: 1101
e: 111
f: 0
c: 100
d: 101
a: 1100
b: 1101
e: 111
Total number of bits needed = 224
Hence, number of bits saved = 800 - 224 = 576
See here for complete explanation and algorithm.
Hence, number of bits saved = 800 - 224 = 576
See here for complete explanation and algorithm.
In a weighted graph, assume that the shortest path from a source 's' to a destination 't' is correctly calculated using a shortest path algorithm. Is the following statement true? If we increase weight of every edge by 1, the shortest path always remains same.- a)Yes
- b)No
Correct answer is option 'B'. Can you explain this answer?
In a weighted graph, assume that the shortest path from a source 's' to a destination 't' is correctly calculated using a shortest path algorithm. Is the following statement true? If we increase weight of every edge by 1, the shortest path always remains same.
a)
Yes
b)
No
|
|
Sanya Agarwal answered |
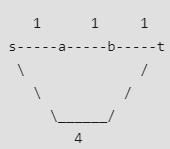
See the following counterexample. There are 4 edges s-a, a-b, b-t and s-t of wights 1, 1, 1 and 4 respectively. The shortest path from s to t is s-a, a-b, b-t. IF we increase weight of every edge by 1, the shortest path changes to s-t.
Which of the following standard algorithms is not a Greedy algorithm?- a)Dijkstra's shortest path algorithm
- b)Prim's algorithm
- c)Kruskal algorithm
- d)Huffman Coding
- e)Bellmen Ford Shortest path algorithm
Correct answer is option 'E'. Can you explain this answer?
Which of the following standard algorithms is not a Greedy algorithm?
a)
Dijkstra's shortest path algorithm
b)
Prim's algorithm
c)
Kruskal algorithm
d)
Huffman Coding
e)
Bellmen Ford Shortest path algorithm

|
Shivam Sharma answered |
The Bellman-Ford algorithm is a graph search algorithm that finds the shortest path between a given source vertex and all other vertices in the graph. This algorithm can be used on both weighted and unweighted graphs.
Like Dijkstra's shortest path algorithm, the Bellman-Ford algorithm is guaranteed to find the shortest path in a graph. Though it is slower than Dijkstra's algorithm, Bellman-Ford is capable of handling graphs that contain negative edge weights, so it is more versatile. It is worth noting that if there exists a negative cycle in the graph, then there is no shortest path. Going around the negative cycle an infinite number of times would continue to decrease the cost of the path (even though the path length is increasing). Because of this, Bellman-Ford can also detect negative cycles which is a useful feature.
Which of the following is true about Huffman Coding.- a)Huffman coding may become lossy in some cases
- b)Huffman Codes may not be optimal lossless codes in some cases
- c)In Huffman coding, no code is prefix of any other code.
- d)All of the above
Correct answer is option 'C'. Can you explain this answer?
Which of the following is true about Huffman Coding.
a)
Huffman coding may become lossy in some cases
b)
Huffman Codes may not be optimal lossless codes in some cases
c)
In Huffman coding, no code is prefix of any other code.
d)
All of the above
|
|
Maheshwar Saha answered |
Huffman Coding
Huffman coding is a lossless data compression algorithm that assigns variable-length codes to characters based on their frequency of occurrence in a given text. It is widely used in data compression applications, such as ZIP files and MP3 audio files.
True statement about Huffman Coding
The correct answer is option 'C', which states that "In Huffman coding, no code is prefix of any other code." This statement is true because of the following reasons:
Prefix Codes
In Huffman coding, the variable-length codes assigned to characters are called prefix codes. A prefix code is a code in which no code word is a prefix of any other code word. For example, consider the following codes:
A -> 0
B -> 10
C -> 110
D -> 111
These codes are prefix codes because no code word is a prefix of any other code word. For instance, the code for B (10) is not a prefix of the code for C (110).
Optimality of Huffman Codes
Huffman codes are optimal prefix codes, which means that they have the minimum average codeword length among all prefix codes that can be generated from the same frequency distribution. This optimality property of Huffman codes ensures that they provide the best possible compression ratio for a given text.
Losslessness of Huffman Coding
Huffman coding is a lossless data compression algorithm, which means that the original text can be recovered exactly from the compressed data. There is no loss of information in the encoding and decoding process.
Conclusion
In conclusion, the true statement about Huffman coding is that it generates prefix codes in which no code word is a prefix of any other code word. This property ensures the uniqueness of the codes and enables their efficient decoding. Huffman codes are optimal prefix codes that provide the best compression ratio for a given text, and they are lossless, which means that the original text can be recovered exactly from the compressed data.
Huffman coding is a lossless data compression algorithm that assigns variable-length codes to characters based on their frequency of occurrence in a given text. It is widely used in data compression applications, such as ZIP files and MP3 audio files.
True statement about Huffman Coding
The correct answer is option 'C', which states that "In Huffman coding, no code is prefix of any other code." This statement is true because of the following reasons:
Prefix Codes
In Huffman coding, the variable-length codes assigned to characters are called prefix codes. A prefix code is a code in which no code word is a prefix of any other code word. For example, consider the following codes:
A -> 0
B -> 10
C -> 110
D -> 111
These codes are prefix codes because no code word is a prefix of any other code word. For instance, the code for B (10) is not a prefix of the code for C (110).
Optimality of Huffman Codes
Huffman codes are optimal prefix codes, which means that they have the minimum average codeword length among all prefix codes that can be generated from the same frequency distribution. This optimality property of Huffman codes ensures that they provide the best possible compression ratio for a given text.
Losslessness of Huffman Coding
Huffman coding is a lossless data compression algorithm, which means that the original text can be recovered exactly from the compressed data. There is no loss of information in the encoding and decoding process.
Conclusion
In conclusion, the true statement about Huffman coding is that it generates prefix codes in which no code word is a prefix of any other code word. This property ensures the uniqueness of the codes and enables their efficient decoding. Huffman codes are optimal prefix codes that provide the best compression ratio for a given text, and they are lossless, which means that the original text can be recovered exactly from the compressed data.
Six files F1, F2, F3, F4, F5 and F6 have 100, 200, 50, 80, 120, 150 records respectively. In what order should they be stored so as to optimize act. Assume each file is accessed with the same frequency- a)F3, F4, F1, F5, F6, F2
- b)F2, F6, F5, F1, F4, F3
- c)F1, F2, F3, F4, F5, F6
- d)Ordering is immaterial as all files are accessed with the same frequency.
Correct answer is option 'A'. Can you explain this answer?
Six files F1, F2, F3, F4, F5 and F6 have 100, 200, 50, 80, 120, 150 records respectively. In what order should they be stored so as to optimize act. Assume each file is accessed with the same frequency
a)
F3, F4, F1, F5, F6, F2
b)
F2, F6, F5, F1, F4, F3
c)
F1, F2, F3, F4, F5, F6
d)
Ordering is immaterial as all files are accessed with the same frequency.
|
|
Ravi Singh answered |
This question is based on the Optimal Storage on Tape problem which uses greedy approach to find the optimal time to retrieve them.
There are n programs of length L that are to be stored on a computer tape. Associated with each program i is a length Li. So in order to
retrieve these programs most optimally, we need to store them in the non-decreasing order of length Li.
So, the correct order is F3, F4, F1, F5, F6, F2
There are n programs of length L that are to be stored on a computer tape. Associated with each program i is a length Li. So in order to
retrieve these programs most optimally, we need to store them in the non-decreasing order of length Li.
So, the correct order is F3, F4, F1, F5, F6, F2
Define Rn to be the maximum amount earned by cutting a rod of length n meters into one or more pieces of integer length and selling them. For i>0, let p[i] denote the selling price of a rod whose length is i meters. Consider the array of prices:
p[1]=1, p[2]=5, p[3]=8, p[4]=9, p[5]=10, p[6]=17, p[7]=18
Which of the following statements is/are correct about R7?- a)R7=18
- b)R7=19
- c)R7 is achieved by three different solutions
- d)R7 cannot be achieved by a solution consisting of three pieces
Correct answer is option 'A,C'. Can you explain this answer?
Define Rn to be the maximum amount earned by cutting a rod of length n meters into one or more pieces of integer length and selling them. For i>0, let p[i] denote the selling price of a rod whose length is i meters. Consider the array of prices:
p[1]=1, p[2]=5, p[3]=8, p[4]=9, p[5]=10, p[6]=17, p[7]=18
Which of the following statements is/are correct about R7?
p[1]=1, p[2]=5, p[3]=8, p[4]=9, p[5]=10, p[6]=17, p[7]=18
Which of the following statements is/are correct about R7?
a)
R7=18
b)
R7=19
c)
R7 is achieved by three different solutions
d)
R7 cannot be achieved by a solution consisting of three pieces
|
|
Ravi Singh answered |
According to given data,
Number of pieces Possible max profits with combination of rod size
7 7 (1, 1, 1, 1, 1, 1, 1)
6 10 (2, 1, 1, 1, 1, 1)
5 13 (2, 2, 1, 1, 1)
4 16 (2, 2, 2, 1)
3 18 (2, 2, 3)
2 18 (6, 1)
1 18 (7)
Therefore, Option (A) and (C) are correct.
Number of pieces Possible max profits with combination of rod size
7 7 (1, 1, 1, 1, 1, 1, 1)
6 10 (2, 1, 1, 1, 1, 1)
5 13 (2, 2, 1, 1, 1)
4 16 (2, 2, 2, 1)
3 18 (2, 2, 3)
2 18 (6, 1)
1 18 (7)
Therefore, Option (A) and (C) are correct.
The number of permutations of the characters in LILAC so that no character appears in its original position, if the two L’s are indistinguishable, is ________ . Note - This question was Numerical Type.- a)12
- b)10
- c)8
- d)15
Correct answer is option 'A'. Can you explain this answer?
The number of permutations of the characters in LILAC so that no character appears in its original position, if the two L’s are indistinguishable, is ________ . Note - This question was Numerical Type.
a)
12
b)
10
c)
8
d)
15
|
|
Sanya Agarwal answered |
There are 3 choices for the first slot, and then 2 for the third slot. That leaves one letter out of I,A,C unchosen and there are 2 slots that one might occupy. After that, the L′s must go in the 2 unfilled slots. Hence the answer is,
3×2×1×2 = 12
Option (A) is correct.
3×2×1×2 = 12
Option (A) is correct.
What is the weight of a minimum spanning tree of the following graph ?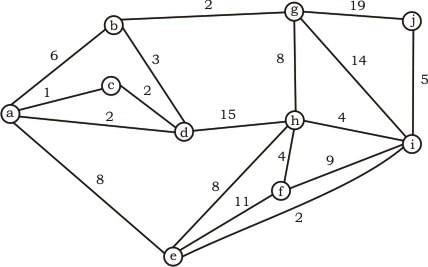
- a)29
- b)31
- c)38
- d)41
Correct answer is option 'B'. Can you explain this answer?
What is the weight of a minimum spanning tree of the following graph ?
a)
29
b)
31
c)
38
d)
41

|
EduRev GATE answered |
(a,c), (a,d), (d,b), (b,g), (g,h), (h,f), (h,i), (i,j), (i,e) = 31 Background required - Minimum Spanning Tree (Prims / Kruskal) In these type of questions, always go for kruskal’s algorithm to find out the the minimum spanning tree as it is easy and there are less chances of doing silly mistakes. Algorithm: Always pick the minimum edge weight and try to add to current forest (Collection of Trees) if no cycle is formed else discard. As soon as u have added n-1 edges to the forest, stop and you have got your minimum spanning tree. See the below image for construction of MST of this question.
Weight of minimum spanning tree = Sum of all the edges in Minimum Spanning tree = 31
Given a weighted graph where weights of all edges are unique (no two edge have same weights), there is always a unique shortest path from a source to destination in such a graph.- a)True
- b)False
Correct answer is option 'B'. Can you explain this answer?
Given a weighted graph where weights of all edges are unique (no two edge have same weights), there is always a unique shortest path from a source to destination in such a graph.
a)
True
b)
False
|
|
Varun Khanna answered |
Explanation:
In a weighted graph where all edge weights are unique, there can be multiple shortest paths from a source to a destination. Therefore, option 'B' is the correct answer.
Why there can be multiple shortest paths?
To understand why there can be multiple shortest paths in such a graph, let's consider an example.
Consider the following weighted graph:
```
A
/ \
3/ \5
/ \
B---2--->C
\ /
4\ /6
\ /
D
```
In this graph, the weights of the edges are unique (3, 2, 4, 5, 6). Now, let's find the shortest path from vertex A to vertex D.
Possible Shortest Paths:
There can be multiple shortest paths from A to D in this graph:
1. A -> B -> D (total weight = 3 + 4 = 7)
2. A -> C -> D (total weight = 5 + 6 = 11)
Both of these paths have unique edge weights and are the shortest paths from A to D.
Conclusion:
In a weighted graph where all edge weights are unique, there can be multiple shortest paths from a source to a destination. Therefore, the statement "there is always a unique shortest path from a source to destination in such a graph" is false.
In a weighted graph where all edge weights are unique, there can be multiple shortest paths from a source to a destination. Therefore, option 'B' is the correct answer.
Why there can be multiple shortest paths?
To understand why there can be multiple shortest paths in such a graph, let's consider an example.
Consider the following weighted graph:
```
A
/ \
3/ \5
/ \
B---2--->C
\ /
4\ /6
\ /
D
```
In this graph, the weights of the edges are unique (3, 2, 4, 5, 6). Now, let's find the shortest path from vertex A to vertex D.
Possible Shortest Paths:
There can be multiple shortest paths from A to D in this graph:
1. A -> B -> D (total weight = 3 + 4 = 7)
2. A -> C -> D (total weight = 5 + 6 = 11)
Both of these paths have unique edge weights and are the shortest paths from A to D.
Conclusion:
In a weighted graph where all edge weights are unique, there can be multiple shortest paths from a source to a destination. Therefore, the statement "there is always a unique shortest path from a source to destination in such a graph" is false.
What is the time complexity of Huffman Coding?- a)O(N)
- b)O(NlogN)
- c)O(N(logN)^2)
- d)O(N^2)
Correct answer is option 'B'. Can you explain this answer?
What is the time complexity of Huffman Coding?
a)
O(N)
b)
O(NlogN)
c)
O(N(logN)^2)
d)
O(N^2)
|
|
Nilesh Saha answered |
O(nlogn) where n is the number of unique characters. If there are n nodes, extractMin() is called 2*(n – 1) times. extractMin() takes O(logn) time as it calles minHeapify(). So, overall complexity is O(nlogn). See here for more details of the algorithm.
Which of the following algorithms solves the all pair shortest path problem?- a)Dijkstra’s algorithm
- b)Floyd’s algorithm
- c)Prim’s algorithm
- d)Warshall’s algorithm
Correct answer is option 'B'. Can you explain this answer?
Which of the following algorithms solves the all pair shortest path problem?
a)
Dijkstra’s algorithm
b)
Floyd’s algorithm
c)
Prim’s algorithm
d)
Warshall’s algorithm
|
|
Aman Menon answered |
Dijkstra’s algorithm solves single source shortest path problem.
Warshall’s algorithm finds transitive closure of a given graph.
Prim’s algorithm constructs a minimum cost spanning tree for a given weighted graph.
Warshall’s algorithm finds transitive closure of a given graph.
Prim’s algorithm constructs a minimum cost spanning tree for a given weighted graph.
In the graph given in above question question, what is the minimum possible weight of a path P from vertex 1 to vertex 2 in this graph such that P contains at most 3 edges?- a)7
- b)8
- c)9
- d)10
Correct answer is option 'B'. Can you explain this answer?
In the graph given in above question question, what is the minimum possible weight of a path P from vertex 1 to vertex 2 in this graph such that P contains at most 3 edges?
a)
7
b)
8
c)
9
d)
10
|
|
Sounak Joshi answered |
Explanation:
Understanding the graph:
- The graph given consists of vertices connected by edges, each edge has a weight associated with it.
- We need to find the minimum possible weight of a path from vertex 1 to vertex 2 with at most 3 edges.
Finding the path with minimum weight:
- To find the minimum weight path from vertex 1 to vertex 2 with at most 3 edges, we need to explore the possible paths.
- By examining the graph, we can see that the following paths are possible:
- Path 1: 1 -> 2 (weight 8)
- Path 2: 1 -> 3 -> 2 (weight 10)
- Path 3: 1 -> 4 -> 2 (weight 9)
Determining the minimum weight path:
- Among the possible paths, the path with the minimum weight is Path 1: 1 -> 2 with a weight of 8.
- Therefore, the minimum possible weight of a path from vertex 1 to vertex 2 with at most 3 edges is 8.
Conclusion:
- The minimum possible weight of a path from vertex 1 to vertex 2 with at most 3 edges in the given graph is 8.
Understanding the graph:
- The graph given consists of vertices connected by edges, each edge has a weight associated with it.
- We need to find the minimum possible weight of a path from vertex 1 to vertex 2 with at most 3 edges.
Finding the path with minimum weight:
- To find the minimum weight path from vertex 1 to vertex 2 with at most 3 edges, we need to explore the possible paths.
- By examining the graph, we can see that the following paths are possible:
- Path 1: 1 -> 2 (weight 8)
- Path 2: 1 -> 3 -> 2 (weight 10)
- Path 3: 1 -> 4 -> 2 (weight 9)
Determining the minimum weight path:
- Among the possible paths, the path with the minimum weight is Path 1: 1 -> 2 with a weight of 8.
- Therefore, the minimum possible weight of a path from vertex 1 to vertex 2 with at most 3 edges is 8.
Conclusion:
- The minimum possible weight of a path from vertex 1 to vertex 2 with at most 3 edges in the given graph is 8.
Let s and t be two vertices in a undirected graph G + (V, E) having distinct positive edge weights. Let [X, Y] be a partition of V such that s ∈ X and t ∈ Y. Consider the edge e having the minimum weight amongst all those edges that have one vertex in X and one vertex in Y The edge e must definitely belong to:- a)the minimum weighted spanning tree of G
- b)the weighted shortest path from s to t
- c)each path from s to t
- d)the weighted longest path from s to t
Correct answer is option 'A'. Can you explain this answer?
Let s and t be two vertices in a undirected graph G + (V, E) having distinct positive edge weights. Let [X, Y] be a partition of V such that s ∈ X and t ∈ Y. Consider the edge e having the minimum weight amongst all those edges that have one vertex in X and one vertex in Y The edge e must definitely belong to:
a)
the minimum weighted spanning tree of G
b)
the weighted shortest path from s to t
c)
each path from s to t
d)
the weighted longest path from s to t
|
|
Ravi Singh answered |
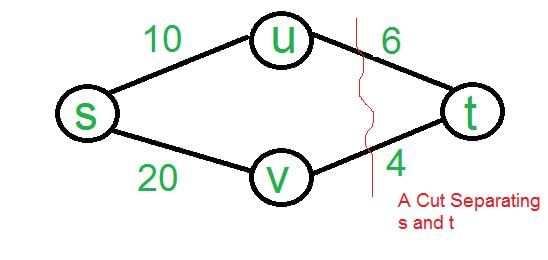
The minimum weight edge on any s-t cut is always part of MST. This is called Cut Property. This is the idea used in Prim's algorithm. The minimum weight cut edge is always a minimum spanning tree edge. Why B (the weighted shortest path from s to t) is not an answer? See below example, edge 4 (lightest in highlighted red cut from s to t) is not part of shortest path.
Suppose the letters a, b, c, d, e, f have probabilities 1/2, 1/4, 1/8, 1/16, 1/32, 1/32 respectively. What is the average length of Huffman codes?- a)3
- b)2.1875
- c)2.25
- d)1.9375
Correct answer is option 'D'. Can you explain this answer?
Suppose the letters a, b, c, d, e, f have probabilities 1/2, 1/4, 1/8, 1/16, 1/32, 1/32 respectively. What is the average length of Huffman codes?
a)
3
b)
2.1875
c)
2.25
d)
1.9375
|
|
Maulik Pillai answered |
We get the following Huffman Tree after applying Huffman Coding Algorithm. The idea is to keep the least probable characters as low as possible by picking them first.
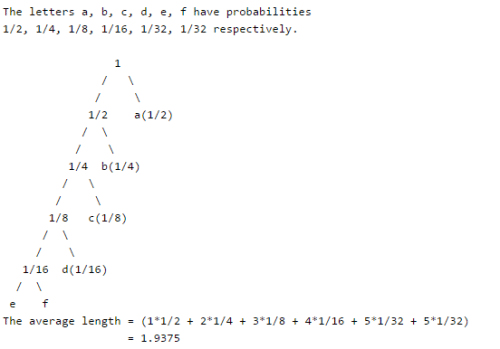
6 files F1, F2, F3, F4, F5and F6 have 100, 200, 50, 80, 120, 150 records respectively. In what order should they be stored so as to optimize act. Assume each file is accessed with the same frequency.- a)F3,F4, F1.F5, F6, F2
- b)F2, F6, F5, F1.F4, F3
- c)F1,F2, F3, F4, F5, F6
- d)Ordering is immaterial as all files are accessed with the same frequency
Correct answer is option 'A'. Can you explain this answer?
6 files F1, F2, F3, F4, F5and F6 have 100, 200, 50, 80, 120, 150 records respectively. In what order should they be stored so as to optimize act. Assume each file is accessed with the same frequency.
a)
F3,F4, F1.F5, F6, F2
b)
F2, F6, F5, F1.F4, F3
c)
F1,F2, F3, F4, F5, F6
d)
Ordering is immaterial as all files are accessed with the same frequency

|
Abhay Bhadouriya answered |
Since the access is sequential, greater the distance, greater will be the access time. Since all the files are referenced with equal frequency, overall access time can be reduced by arranging them as then ascending order of record as in option (a).
The number of distinct minimum spanning trees for the weighted graph below is ____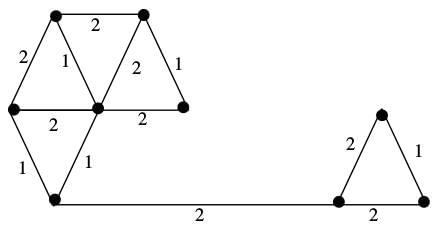
- a)4
- b)5
- c)6
- d)7
Correct answer is option 'C'. Can you explain this answer?
The number of distinct minimum spanning trees for the weighted graph below is ____
a)
4
b)
5
c)
6
d)
7

|
Cstoppers Instructors answered |
Below diagram shows a minimum spanning tree. Highlighted (in green) are the edges picked to make the MST.
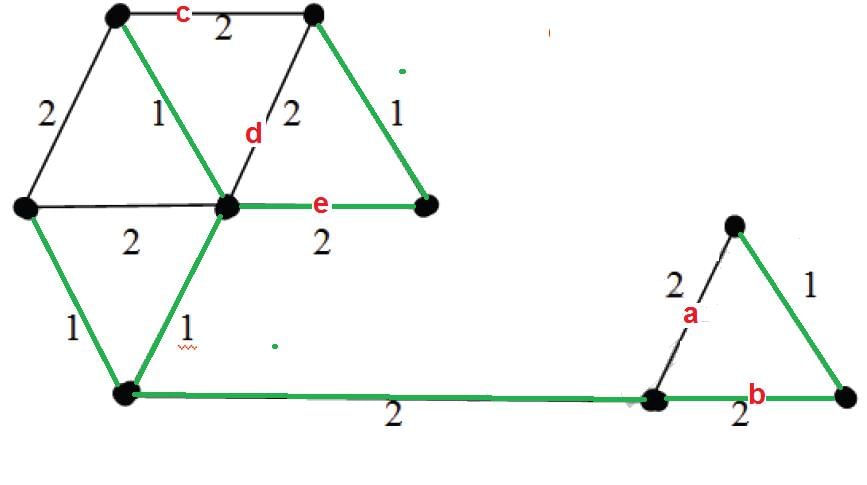
In the right side of MST, we could either pick edge ‘a’ or ‘b’. In the left side, we could either pick ‘c’ or ‘d’ or ‘e’ in MST. There are 2 options for one edge to be picked and 3 options for another edge to be picked. Therefore, total 2*3 possible MSTs.
In question #2, which of the following represents the word "dead"?- a)1011111100101
- b)0100000011010
- c)Both A and B
- d)None of these
Correct answer is option 'C'. Can you explain this answer?
In question #2, which of the following represents the word "dead"?
a)
1011111100101
b)
0100000011010
c)
Both A and B
d)
None of these
|
|
Shalini Rane answered |
The Huffman Tree generated is:
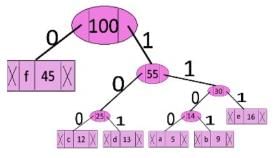

The word dead can be represented as: 101 111 1100 101 However, the alternative codeword can also be found by assigning 1 to the left edge and 0 to the right edge of the tree, i.e. dead can also be represented as: 010 000 0011 010 See here for more details of the algorithm.
Consider a weighted complete graph G on the vertex set {v1, v2, .... vn} such that the weight of the edge (vi, vj) is 2 | i - j | .The weight of a minimum - a)n-1
- b)2n-2
- c)n/2
- d)n2
Correct answer is option 'B'. Can you explain this answer?
Consider a weighted complete graph G on the vertex set {v1, v2, .... vn} such that the weight of the edge (vi, vj) is 2 | i - j | .The weight of a minimum
a)
n-1
b)
2n-2
c)
n/2
d)
n2
|
|
Moumita Yadav answered |
Weighted Complete Graph:
A weighted complete graph is a graph where every pair of vertices is connected by an edge, and each edge has a weight assigned to it.
Weight of Edges:
In this graph, the weight of the edge (vi, vj) is given by the formula 2 | i - j |, where i and j are the indices of the vertices.
Minimum Weight:
We need to find the weight of a minimum spanning tree (MST) in this graph. An MST is a tree that connects all the vertices in the graph with the minimum total weight.
Algorithm:
To find the weight of the MST in this graph, we can use Kruskal's algorithm or Prim's algorithm.
Kruskal's Algorithm:
1. Sort all the edges in non-decreasing order of their weights.
2. Initialize an empty set of edges, which will form the MST.
3. Iterate over the sorted edges and add each edge to the MST set if it doesn't form a cycle.
4. Stop when there are n-1 edges in the MST set, where n is the number of vertices in the graph.
Explanation:
In this graph, there are n vertices labeled v1, v2, ..., vn. Since it is a complete graph, there will be n*(n-1)/2 edges.
The weight of an edge (vi, vj) is given by 2 | i - j |. Let's consider two cases:
1. When i < />
- The weight of the edge (vi, vj) is 2(j - i).
- For any vertex vi, there are (n - i) vertices with indices greater than i.
- So, the total weight contributed by vertex vi in the MST is 2(j - i) * (n - i).
2. When i > j:
- The weight of the edge (vi, vj) is 2(i - j).
- For any vertex vi, there are (i - 1) vertices with indices smaller than i.
- So, the total weight contributed by vertex vi in the MST is 2(i - j) * (i - 1).
Weight of MST:
To find the weight of the MST, we need to sum up the contributions from each vertex:
Weight of MST = Σ [2(j - i) * (n - i)] + Σ [2(i - j) * (i - 1)]
Simplification:
By simplifying the above expressions, we can show that the weight of the MST is 2(n-1)(n-2).
Conclusion:
The weight of the MST in this graph is 2(n-1)(n-2), which is equivalent to 2n-2. Therefore, the correct answer is option 'B'.
A weighted complete graph is a graph where every pair of vertices is connected by an edge, and each edge has a weight assigned to it.
Weight of Edges:
In this graph, the weight of the edge (vi, vj) is given by the formula 2 | i - j |, where i and j are the indices of the vertices.
Minimum Weight:
We need to find the weight of a minimum spanning tree (MST) in this graph. An MST is a tree that connects all the vertices in the graph with the minimum total weight.
Algorithm:
To find the weight of the MST in this graph, we can use Kruskal's algorithm or Prim's algorithm.
Kruskal's Algorithm:
1. Sort all the edges in non-decreasing order of their weights.
2. Initialize an empty set of edges, which will form the MST.
3. Iterate over the sorted edges and add each edge to the MST set if it doesn't form a cycle.
4. Stop when there are n-1 edges in the MST set, where n is the number of vertices in the graph.
Explanation:
In this graph, there are n vertices labeled v1, v2, ..., vn. Since it is a complete graph, there will be n*(n-1)/2 edges.
The weight of an edge (vi, vj) is given by 2 | i - j |. Let's consider two cases:
1. When i < />
- The weight of the edge (vi, vj) is 2(j - i).
- For any vertex vi, there are (n - i) vertices with indices greater than i.
- So, the total weight contributed by vertex vi in the MST is 2(j - i) * (n - i).
2. When i > j:
- The weight of the edge (vi, vj) is 2(i - j).
- For any vertex vi, there are (i - 1) vertices with indices smaller than i.
- So, the total weight contributed by vertex vi in the MST is 2(i - j) * (i - 1).
Weight of MST:
To find the weight of the MST, we need to sum up the contributions from each vertex:
Weight of MST = Σ [2(j - i) * (n - i)] + Σ [2(i - j) * (i - 1)]
Simplification:
By simplifying the above expressions, we can show that the weight of the MST is 2(n-1)(n-2).
Conclusion:
The weight of the MST in this graph is 2(n-1)(n-2), which is equivalent to 2n-2. Therefore, the correct answer is option 'B'.
In an unweighted, undirected connected graph, the shortest path from a node S to every other node is computed most efficiently, in terms of time complexity by- a)Dijkstra’s algorithm starting from S
- b)Warshall’s algorithm
- c)Performing a DFS starting from S
- d)Performing a BFS starting from S
Correct answer is option 'D'. Can you explain this answer?
In an unweighted, undirected connected graph, the shortest path from a node S to every other node is computed most efficiently, in terms of time complexity by
a)
Dijkstra’s algorithm starting from S
b)
Warshall’s algorithm
c)
Performing a DFS starting from S
d)
Performing a BFS starting from S
|
|
Cstoppers Instructors answered |
* Time Comlexity of the Dijkstra’s algorithm is O(|V|^2 + E)
* Time Comlexity of the Warshall’s algorithm is O(|V|^3)
* DFS cannot be used for finding shortest paths
* BFS can be used for unweighted graphs. Time Complexity for BFS is O(|E| + |V|)
* Time Comlexity of the Warshall’s algorithm is O(|V|^3)
* DFS cannot be used for finding shortest paths
* BFS can be used for unweighted graphs. Time Complexity for BFS is O(|E| + |V|)
Consider the weights and values of items listed below. Note that there is only one unit of each item.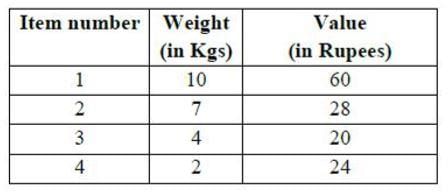 The task is to pick a subset of these items such that their total weight is no more than 11 Kgs and their total value is maximized. Moreover, no item may be split. The total value of items picked by an optimal algorithm is denoted by Vopt. A greedy algorithm sorts the items by their value-to-weight ratios in descending order and packs them greedily, starting from the first item in the ordered list. The total value of items picked by the greedy algorithm is denoted by Vgreedy. The value of Vopt − Vgreedy is ______ .Note -This was Numerical Type question.
The task is to pick a subset of these items such that their total weight is no more than 11 Kgs and their total value is maximized. Moreover, no item may be split. The total value of items picked by an optimal algorithm is denoted by Vopt. A greedy algorithm sorts the items by their value-to-weight ratios in descending order and packs them greedily, starting from the first item in the ordered list. The total value of items picked by the greedy algorithm is denoted by Vgreedy. The value of Vopt − Vgreedy is ______ .Note -This was Numerical Type question.- a)16
- b)8
- c)44
- d)60
Correct answer is option 'A'. Can you explain this answer?
Consider the weights and values of items listed below. Note that there is only one unit of each item.
The task is to pick a subset of these items such that their total weight is no more than 11 Kgs and their total value is maximized. Moreover, no item may be split. The total value of items picked by an optimal algorithm is denoted by Vopt. A greedy algorithm sorts the items by their value-to-weight ratios in descending order and packs them greedily, starting from the first item in the ordered list. The total value of items picked by the greedy algorithm is denoted by Vgreedy. The value of Vopt − Vgreedy is ______ .
Note -This was Numerical Type question.
a)
16
b)
8
c)
44
d)
60
|
|
Ravi Singh answered |
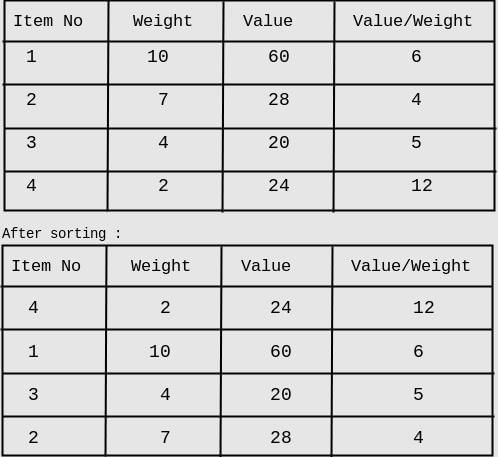
First we will pick item_4 (Value weight ratio is highest). Second highest is item_1, but cannot be picked because of its weight. Now item_3 shall be picked. item_2 cannot be included because of its weight. Therefore, overall profit by Vgreedy = 20+24 = 44 Hence, Vopt - Vgreedy = 60-44 = 16 So, answer is 16.
Which of the following statement(s)is / are correct regarding Bellman-Ford shortest path algorithm?
P: Always finds a negative weighted cycle, if one exist s.
Q: Finds whether any negative weighted cycle is reachable from the source. - a)P Only
- b)Q Only
- c)Both P and Q
- d)Neither P nor Q
Correct answer is option 'B'. Can you explain this answer?
Which of the following statement(s)is / are correct regarding Bellman-Ford shortest path algorithm?
P: Always finds a negative weighted cycle, if one exist s.
Q: Finds whether any negative weighted cycle is reachable from the source.
P: Always finds a negative weighted cycle, if one exist s.
Q: Finds whether any negative weighted cycle is reachable from the source.
a)
P Only
b)
Q Only
c)
Both P and Q
d)
Neither P nor Q
|
|
Sanya Agarwal answered |
Bellman-Ford shortest path algorithm is a single source shortest path algorithm. So it can only find cycles which are reachable from a given source, not any negative weight cycle. Consider a disconnected where a negative weight cycle is not reachable from the source at all. If there is a negative weight cycle, then it will appear in shortest path as the negative weight cycle will always form a shorter path when iterated through the cycle again and again.
An undirected graph G has n nodes. Its adjacency matrix is given by an n × n square matrix whose(i) diagonal elements are 0‘s and(ii) non-diagonal elements are 1‘s.which one of the following is TRUE?- a)Graph G has no minimum spanning tree (MST)
- b)Graph G has a unique MST of cost n-1
- c)Graph G has multiple distinct MSTs, each of cost n-1
- d)Graph G has multiple spanning trees of different costs
Correct answer is option 'C'. Can you explain this answer?
An undirected graph G has n nodes. Its adjacency matrix is given by an n × n square matrix whose
(i) diagonal elements are 0‘s and
(ii) non-diagonal elements are 1‘s.
which one of the following is TRUE?
a)
Graph G has no minimum spanning tree (MST)
b)
Graph G has a unique MST of cost n-1
c)
Graph G has multiple distinct MSTs, each of cost n-1
d)
Graph G has multiple spanning trees of different costs
|
|
Sanya Agarwal answered |
If all non diagonal elements are 1, then every vertex is connected to every other vertex in the graph with an edge of weight 1. Such a graph has multiple distinct MSTs with cost n-1.
Let G = (V, E) be a simple undirected graph, and s be a particular vertex in it called the source. For x ∈ V, let d(x) denote the shortest distance in G from s to x. A breadth first search (BFS) is performed starting at s. Let T be the resultant BFS tree. If (u, v) is an edge of G that is not in T, then which one of the following CANNOT be the value of d(u) – d(v)?- a)-1
- b)0
- c)1
- d)2
Correct answer is option 'D'. Can you explain this answer?
Let G = (V, E) be a simple undirected graph, and s be a particular vertex in it called the source. For x ∈ V, let d(x) denote the shortest distance in G from s to x. A breadth first search (BFS) is performed starting at s. Let T be the resultant BFS tree. If (u, v) is an edge of G that is not in T, then which one of the following CANNOT be the value of d(u) – d(v)?
a)
-1
b)
0
c)
1
d)
2
|
|
Tanishq Malik answered |
Understanding BFS and Distance in Graphs
When performing a Breadth First Search (BFS) on a graph G, the distance from the source vertex s to any vertex x, denoted as d(x), reflects the minimum number of edges traversed to reach x. The BFS tree T captures the shortest paths from s to all reachable vertices.
Key Points on Edges Not in T
For an edge (u, v) that is not part of the BFS tree T, we can analyze the possible values of d(u) - d(v):
- d(u) - d(v) = -1: This means d(u) = d(v) - 1. This situation can occur when vertex v is at a level deeper than u in the BFS tree, indicating that u is a parent of v in some path not taken by BFS.
- d(u) - d(v) = 0: This implies d(u) = d(v). This can happen if both vertices are at the same level in the BFS tree and are not directly connected in the tree but are connected by the edge (u, v).
- d(u) - d(v) = 1: In this case, d(u) = d(v) + 1. This suggests that u is one level deeper than v, which can occur if v is a neighbor of s and u is further away in the graph.
Why d(u) - d(v) = 2 Cannot Occur
- BFS Properties: BFS explores all neighbors at the current level before moving to the next. Therefore, if (u, v) is an edge not in T and u is at a greater distance than v, the maximum difference in levels is 1.
- Conclusion: Thus, the value d(u) - d(v) = 2 indicates that u is two levels deeper than v, which contradicts the BFS traversal property that ensures all vertices at a given level are explored before moving deeper.
In summary, while -1, 0, and 1 are feasible distances between u and v, a distance of 2 is not possible in the context of BFS.
When performing a Breadth First Search (BFS) on a graph G, the distance from the source vertex s to any vertex x, denoted as d(x), reflects the minimum number of edges traversed to reach x. The BFS tree T captures the shortest paths from s to all reachable vertices.
Key Points on Edges Not in T
For an edge (u, v) that is not part of the BFS tree T, we can analyze the possible values of d(u) - d(v):
- d(u) - d(v) = -1: This means d(u) = d(v) - 1. This situation can occur when vertex v is at a level deeper than u in the BFS tree, indicating that u is a parent of v in some path not taken by BFS.
- d(u) - d(v) = 0: This implies d(u) = d(v). This can happen if both vertices are at the same level in the BFS tree and are not directly connected in the tree but are connected by the edge (u, v).
- d(u) - d(v) = 1: In this case, d(u) = d(v) + 1. This suggests that u is one level deeper than v, which can occur if v is a neighbor of s and u is further away in the graph.
Why d(u) - d(v) = 2 Cannot Occur
- BFS Properties: BFS explores all neighbors at the current level before moving to the next. Therefore, if (u, v) is an edge not in T and u is at a greater distance than v, the maximum difference in levels is 1.
- Conclusion: Thus, the value d(u) - d(v) = 2 indicates that u is two levels deeper than v, which contradicts the BFS traversal property that ensures all vertices at a given level are explored before moving deeper.
In summary, while -1, 0, and 1 are feasible distances between u and v, a distance of 2 is not possible in the context of BFS.
Suppose the letters a, b, c, d, e, f have probabilities 1/2, 1/4, 1/8, 1/16, 1/32, 1/32 respectively. Which of the following is the Huffman code for the letter a, b, c, d, e, f?- a)0, 10, 110, 1110, 11110, 11111
- b)11, 10, 011, 010, 001, 000
- c)11, 10, 01, 001, 0001, 0000
- d)110, 100, 010, 000, 001, 111
Correct answer is option 'A'. Can you explain this answer?
Suppose the letters a, b, c, d, e, f have probabilities 1/2, 1/4, 1/8, 1/16, 1/32, 1/32 respectively. Which of the following is the Huffman code for the letter a, b, c, d, e, f?
a)
0, 10, 110, 1110, 11110, 11111
b)
11, 10, 011, 010, 001, 000
c)
11, 10, 01, 001, 0001, 0000
d)
110, 100, 010, 000, 001, 111
|
|
Subhankar Shah answered |
We get the following Huffman Tree after applying Huffman Coding Algorithm. The idea is to keep the least probable characters as low as possible by picking them first.

Which of the following is true about Huffman Coding.- a)Huffman coding may become lossy in some cases
- b)Huffman Codes may not be optimal lossless codes in some cases
- c)In Huffman coding, no code is prefix of any other code
- d)All of the above
Correct answer is option 'C'. Can you explain this answer?
Which of the following is true about Huffman Coding.
a)
Huffman coding may become lossy in some cases
b)
Huffman Codes may not be optimal lossless codes in some cases
c)
In Huffman coding, no code is prefix of any other code
d)
All of the above
|
|
Sanya Agarwal answered |
Huffman coding is a lossless data compression algorithm. The codes assigned to input characters are Prefix Codes, means the codes are assigned in such a way that the code assigned to one character is not prefix of code assigned to any other character. This is how Huffman Coding makes sure that there is no ambiguity when decoding.
A networking company uses a compression technique to encode the message before transmitting over the network. Suppose the message contains the following characters with their frequency:
character Frequency
a 5
b 9
c 12
d 13
e 16
f 45Note : Each character in input message takes 1 byte. If the compression technique used is Huffman Coding, how many bits will be saved in the message?- a)224
- b)800
- c)576
- d)324
Correct answer is option 'C'. Can you explain this answer?
A networking company uses a compression technique to encode the message before transmitting over the network. Suppose the message contains the following characters with their frequency:
character Frequency
a 5
b 9
c 12
d 13
e 16
f 45
character Frequency
a 5
b 9
c 12
d 13
e 16
f 45
Note : Each character in input message takes 1 byte. If the compression technique used is Huffman Coding, how many bits will be saved in the message?
a)
224
b)
800
c)
576
d)
324
|
|
Sanya Agarwal answered |
Total number of characters in the message = 100.
Each character takes 1 byte. So total number of bits needed = 800.
Each character takes 1 byte. So total number of bits needed = 800.
After Huffman Coding, the characters can be represented with:
f: 0
c: 100
d: 101
a: 1100
b: 1101
e: 111
Total number of bits needed = 224
Hence, number of bits saved = 800 - 224 = 576
See here for complete explanation and algorithm.
f: 0
c: 100
d: 101
a: 1100
b: 1101
e: 111
Total number of bits needed = 224
Hence, number of bits saved = 800 - 224 = 576
See here for complete explanation and algorithm.
Let G{V, E) an undirected graph with positive edge weights. Dijkstra’s single source-shortest path algorithmn can be implemented using the binary heap data structure with time complexity?
- a)O(|V|2)
- b)O ( ( | E | + |V| ) log |V I )
- c)O ( l V| log |V|)
- d)O ( l E l + | V | log | V I )
Correct answer is option 'B'. Can you explain this answer?
Let G{V, E) an undirected graph with positive edge weights. Dijkstra’s single source-shortest path algorithmn can be implemented using the binary heap data structure with time complexity?
a)
O(|V|2)
b)
O ( ( | E | + |V| ) log |V I )
c)
O ( l V| log |V|)
d)
O ( l E l + | V | log | V I )
|
|
Arnab Sengupta answered |
Correct answer is B.
O ( ( | E | + |V| ) log |V I )
O ( ( | E | + |V| ) log |V I )
Let G be an undirected connected graph with distinct edge weights. Let emax be the edge with maximum weight and emin the edge with minimum weight. Which of the following statements is false?a) Every minimum spanning tree of G must contain eminb) No minimum spanning tree contains emax
c) If emax is in a minimum spanning tree, then its removal must disconnect Gd) G has a unique minimum spanning treeCorrect answer is option 'B'. Can you explain this answer?
b) No minimum spanning tree contains emax
|
|
Pranav Patel answered |
All edges are distinct weights.
Removal of emax may not disconnect G, because other edges may cover the vertices incident with emax.
Removal of emax may not disconnect G, because other edges may cover the vertices incident with emax.
Kruskal’s algorithm for finding a minimum spanning tree of a weighted graph G with n vertices and m edges has the time complexity of- a)O(n2)
- b)O(mn)
- c)O(m + n)
- d)O(m log n)
Correct answer is option 'D'. Can you explain this answer?
Kruskal’s algorithm for finding a minimum spanning tree of a weighted graph G with n vertices and m edges has the time complexity of
a)
O(n2)
b)
O(mn)
c)
O(m + n)
d)
O(m log n)
|
|
Keerthana Sarkar answered |
Kruskal’s algorithm time complexity
= O(e log v)
= O(m log n)
= O(e log v)
= O(m log n)
Given a directed graph where weight of every edge is same, we can efficiently find shortest path from a given source to destination using?- a)Breadth First Traversal
- b)Dijkstra's Shortest Path Algorithm
- c)Neither Breadth First Traversal nor Dijkstra's algorithm can be used
- d)Depth First Search
Correct answer is option 'A'. Can you explain this answer?
Given a directed graph where weight of every edge is same, we can efficiently find shortest path from a given source to destination using?
a)
Breadth First Traversal
b)
Dijkstra's Shortest Path Algorithm
c)
Neither Breadth First Traversal nor Dijkstra's algorithm can be used
d)
Depth First Search
|
|
Sanya Agarwal answered |
With BFS, we first find explore vertices at one edge distance, then all vertices at 2 edge distance, and so on.
The length of the path from v5 to v6 in the MST of previous question with n = 10 is- a)11
- b)25
- c)31
- d)41
Correct answer is option 'C'. Can you explain this answer?
The length of the path from v5 to v6 in the MST of previous question with n = 10 is
a)
11
b)
25
c)
31
d)
41
|
|
Sanya Agarwal answered |
Any MST which has more than 5 nodes will have the same distance between v5 and v6 as the basic structure of all MSTs (with more than 5 nodes) would be following.

Distance between v5 and v6 = 3 + 4 + 6 + 8 + 10 = 31
A text is made up of the characters a, b, c, d, e each occurring with the probability 0.11, 0.40, 0.16, 0.09 and 0.24 respectively. The optimal Huffman coding technique will have the average length of:- a)2.40
- b)2.16
- c)2.26
- d)2.15
Correct answer is option 'B'. Can you explain this answer?
A text is made up of the characters a, b, c, d, e each occurring with the probability 0.11, 0.40, 0.16, 0.09 and 0.24 respectively. The optimal Huffman coding technique will have the average length of:
a)
2.40
b)
2.16
c)
2.26
d)
2.15
|
|
Sanya Agarwal answered |
a = 0.11 b = 0.40 c = 0.16 d = 0.09 e = 0.24 we will draw a huffman tree:
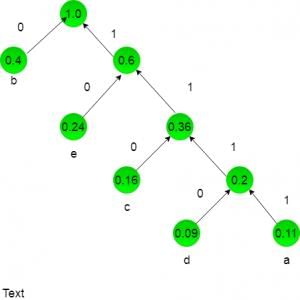
now huffman coding for character:
a = 1111
b = 0
c = 110
d = 1111
e = 10
lenghth for each character = no of bits * frequency of occurence:
a = 4 * 0.11
= 0.44
b = 1 * 0.4
= 0.4
c = 3 * 0.16
= 0.48
d = 4 * 0.09
= 0.36
e = 2 * 0.24
= 0.48
Now add these lenght for average length:
0.44 + 0.4 + 0.48 + 0.36 + 0.48 = 2.16
b = 0
c = 110
d = 1111
e = 10
lenghth for each character = no of bits * frequency of occurence:
a = 4 * 0.11
= 0.44
b = 1 * 0.4
= 0.4
c = 3 * 0.16
= 0.48
d = 4 * 0.09
= 0.36
e = 2 * 0.24
= 0.48
Now add these lenght for average length:
0.44 + 0.4 + 0.48 + 0.36 + 0.48 = 2.16
Which of the following is true about Kruskal and Prim MST algorithms? Assume that Prim is implemented for adjacency list representation using Binary Heap and Kruskal is implemented using union by rank.- a)Worst case time complexity of both algorithms is same.
- b)Worst case time complexity of Kruskal is better than Prim
- c)Worst case time complexity of Prim is better than Kruskal
Correct answer is option 'A'. Can you explain this answer?
Which of the following is true about Kruskal and Prim MST algorithms? Assume that Prim is implemented for adjacency list representation using Binary Heap and Kruskal is implemented using union by rank.
a)
Worst case time complexity of both algorithms is same.
b)
Worst case time complexity of Kruskal is better than Prim
c)
Worst case time complexity of Prim is better than Kruskal
|
|
Yash Patel answered |
There are differences between both the algorithms like Kruskal's algorithm's time complexity is O(E log V), V being the number of vertices. Prim's algorithm gives connected component as well as it works only on connected graph. Prim's algorithm runs faster in dense graphs. Kruskal's algorithm runs faster in sparse graphs.
but Worst case time complexity of both algorithms is same.
Let G be an undirected connected graph with distinct edge weight. Let emax be the edge with maximum weight and emin the edge with minimum weight. Which of the following statements is false?- a)Every minimum spanning tree of G must contain emin
- b)If emax is in a minimum spanning tree, then its removal must disconnect G
- c)No minimum spanning tree contains emax
- d)G has a unique minimum spanning tree
Correct answer is option 'C'. Can you explain this answer?
Let G be an undirected connected graph with distinct edge weight. Let emax be the edge with maximum weight and emin the edge with minimum weight. Which of the following statements is false?
a)
Every minimum spanning tree of G must contain emin
b)
If emax is in a minimum spanning tree, then its removal must disconnect G
c)
No minimum spanning tree contains emax
d)
G has a unique minimum spanning tree
|
|
Sanya Agarwal answered |
(a) and (b) are always true. (c) is false because (b) is true. (d) is true because all edge weights are distinct for G.
Let G = (V, E) be an undirected graph with a subgraph G1 = (V1, El). Weights are assigned to edges of G as follows :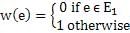 A single-source shortest path algorithm is executed on the weighted graph (V, E, w) with an arbitrary vertex ν1 of V1 as the source. Which of the following can always be inferred from the path costs computed?
A single-source shortest path algorithm is executed on the weighted graph (V, E, w) with an arbitrary vertex ν1 of V1 as the source. Which of the following can always be inferred from the path costs computed?- a)The number of edges in the shortest paths from ν1 to all vertices of G
- b)G1 is connected
- c)V1 forms a clique in G
- d)G1 is a tree
Correct answer is option 'B'. Can you explain this answer?
Let G = (V, E) be an undirected graph with a subgraph G1 = (V1, El). Weights are assigned to edges of G as follows :
A single-source shortest path algorithm is executed on the weighted graph (V, E, w) with an arbitrary vertex ν1 of V1 as the source. Which of the following can always be inferred from the path costs computed?
a)
The number of edges in the shortest paths from ν1 to all vertices of G
b)
G1 is connected
c)
V1 forms a clique in G
d)
G1 is a tree
|
|
Ravi Singh answered |
When shortest path shortest path from v1 (one of the vertices in V1) is computed. G1 is connected if the distance from v1 to any other vertex in V1 is greater than 0, otherwise G1 is disconnected.
Consider a complete undirected graph with vertex set {0, 1, 2, 3, 4}. Entry Wij in the matrix W below is the weight of the edge {i, j}. What is the minimum possible weight of a spanning tree T in this graph such that vertex 0 is a leaf node in the tree T?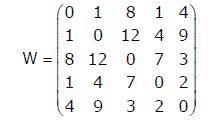
- a)7
- b)8
- c)9
- d)10
Correct answer is option 'D'. Can you explain this answer?
Consider a complete undirected graph with vertex set {0, 1, 2, 3, 4}. Entry Wij in the matrix W below is the weight of the edge {i, j}. What is the minimum possible weight of a spanning tree T in this graph such that vertex 0 is a leaf node in the tree T?
a)
7
b)
8
c)
9
d)
10
|
|
Sanya Agarwal answered |
To get the minimum spanning tree with vertex 0 as leaf, first remove 0th row and 0th column and then get the minimum spanning tree (MST) of the remaining graph. Once we have MST of the remaining graph, connect the MST to vertex 0 with the edge with minimum weight (we have two options as there are two 1s in 0th row).
Suppose we run Dijkstra’s single source shortest-path algorithm on the following edge weighted directed graph with vertex P as the source. In what order do the nodes get included into the set of vertices for which the shortest path distances are finalized?
- a)P, Q, R, S, T, U
- b)P, Q, R, U, S, T
- c)P, Q, R, U, T, S
- d)P, Q, T, R, U, S
Correct answer is option 'B'. Can you explain this answer?
Suppose we run Dijkstra’s single source shortest-path algorithm on the following edge weighted directed graph with vertex P as the source. In what order do the nodes get included into the set of vertices for which the shortest path distances are finalized?
a)
P, Q, R, S, T, U
b)
P, Q, R, U, S, T
c)
P, Q, R, U, T, S
d)
P, Q, T, R, U, S

|
264 Saha answered |
Yes
To implement Dijkstra’s shortest path algorithm on unweighted graphs so that it runs in linear time, the data structure to be used is:- a)Queue
- b)Stack
- c)Heap
- d)B-Tree
Correct answer is option 'A'. Can you explain this answer?
To implement Dijkstra’s shortest path algorithm on unweighted graphs so that it runs in linear time, the data structure to be used is:
a)
Queue
b)
Stack
c)
Heap
d)
B-Tree
|
|
Sanya Agarwal answered |
The shortest path in an un-weighted graph means the smallest number of edges that must be traversed in order to reach the destination in the graph. This is the same problem as solving the weighted version where all the weights happen to be 1. If we use Queue (FIFO) instead of Priority Queue (Min Heap), we get the shortest path in linear time O(|V| + |E|). Basically we do BFS traversal of the graph to get the shortest paths.
Dijkstra’s single source shortest path algorithm when run from vertex a in the below graph, computes the correct shortest path distance to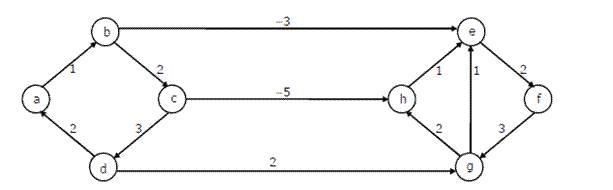
- a)only vertex a
- b)only vertices a, e, f, g, h
- c)only vertices a, b, c, d
- d)all the vertices
Correct answer is option 'D'. Can you explain this answer?
Dijkstra’s single source shortest path algorithm when run from vertex a in the below graph, computes the correct shortest path distance to
a)
only vertex a
b)
only vertices a, e, f, g, h
c)
only vertices a, b, c, d
d)
all the vertices
|
|
Sanya Agarwal answered |
Dijkstra’s single source shortest path is not guaranteed to work for graphs with negative weight edges, but it works for the given graph. Let us see... Let us run the 1st pass b 1 b is minimum, so shortest distance to b is 1. After 1st pass, distances are c 3, e -2. e is minimum, so shortest distance to e is -2 After 2nd pass, distances are c 3, f 0. f is minimum, so shortest distance to f is 0 After 3rd pass, distances are c 3, g 3. Both are same, let us take g. so shortest distance to g is 3. After 4th pass, distances are c 3, h 5 c is minimum, so shortest distance to c is 3 After 5th pass, distances are h -2 h is minimum, so shortest distance to h is -2
Consider the following graph: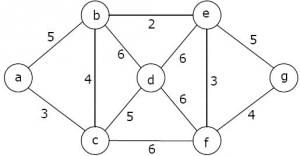 Which one of the following is NOT the sequence of edges added to the minimum spanning tree using Kruskal's algorithm?
Which one of the following is NOT the sequence of edges added to the minimum spanning tree using Kruskal's algorithm?- a)(b,e)(e,f)(a,c)(b,c)(f,g)(c,d)
- b)(b,e)(e,f)(a,c)(f,g)(b,c)(c,d)
- c)(b,e)(a,c)(e,f)(b,c)(f,g)(c,d)
- d)(b,e)(e,f)(b,c)(a,c)(f,g)(c,d)
Correct answer is option 'D'. Can you explain this answer?
Consider the following graph:
Which one of the following is NOT the sequence of edges added to the minimum spanning tree using Kruskal's algorithm?
a)
(b,e)(e,f)(a,c)(b,c)(f,g)(c,d)
b)
(b,e)(e,f)(a,c)(f,g)(b,c)(c,d)
c)
(b,e)(a,c)(e,f)(b,c)(f,g)(c,d)
d)
(b,e)(e,f)(b,c)(a,c)(f,g)(c,d)
|
|
Sanya Agarwal answered |
In the sequence (b, e) (e, f) (b, c) (a, c) (f, g) (c, d) given option D, the edge (a, c) of weight 4 comes after (b, c) of weight 3. In Kruskal's Minimum Spanning Tree Algorithm, we first sort all edges, then consider edges in sorted order, so a higher weight edge cannot come before a lower weight edge.
Which of the following algorithm can be used to efficiently calculate single source shortest paths in a Directed Acyclic Graph?- a)Dijkstra
- b)Bellman-Ford
- c)Topological Sort
- d)Strongly Connected Component
Correct answer is option 'C'. Can you explain this answer?
Which of the following algorithm can be used to efficiently calculate single source shortest paths in a Directed Acyclic Graph?
a)
Dijkstra
b)
Bellman-Ford
c)
Topological Sort
d)
Strongly Connected Component
|
|
Ravi Singh answered |
Using Topological Sort, we can find single source shortest paths in O(V+E) time which is the most efficient algorithm. See following for details. Shortest Path in Directed Acyclic Graph
Is the following statement valid about shortest paths? Given a graph, suppose we have calculated shortest path from a source to all other vertices. If we modify the graph such that weights of all edges is becomes double of the original weight, then the shortest path remains same only the total weight of path changes.- a)True
- b)False
Correct answer is option 'A'. Can you explain this answer?
Is the following statement valid about shortest paths? Given a graph, suppose we have calculated shortest path from a source to all other vertices. If we modify the graph such that weights of all edges is becomes double of the original weight, then the shortest path remains same only the total weight of path changes.
a)
True
b)
False
|
|
Sanya Agarwal answered |
The shortest path remains same. It is like if we change unit of distance from meter to kilo meter, the shortest paths don't change.
Consider the undirected graph below: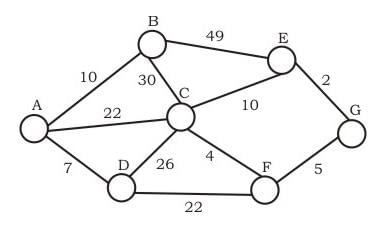 Using Prim's algorithm to construct a minimum spanning tree starting with node A, which one of the following sequences of edges represents a possible order in which the edges would be added to construct the minimum spanning tree?
Using Prim's algorithm to construct a minimum spanning tree starting with node A, which one of the following sequences of edges represents a possible order in which the edges would be added to construct the minimum spanning tree?- a)(E, G), (C, F), (F, G), (A, D), (A, B), (A, C)
- b)(A, D), (A, B), (A, C), (C, F), (G, E), (F, G)
- c)(A, B), (A, D), (D, F), (F, G), (G, E), (F, C)
- d)(A, D), (A, B), (D, F), (F, C), (F, G), (G, E)
Correct answer is option 'D'. Can you explain this answer?
Consider the undirected graph below:
Using Prim's algorithm to construct a minimum spanning tree starting with node A, which one of the following sequences of edges represents a possible order in which the edges would be added to construct the minimum spanning tree?
a)
(E, G), (C, F), (F, G), (A, D), (A, B), (A, C)
b)
(A, D), (A, B), (A, C), (C, F), (G, E), (F, G)
c)
(A, B), (A, D), (D, F), (F, G), (G, E), (F, C)
d)
(A, D), (A, B), (D, F), (F, C), (F, G), (G, E)
|
|
Ravi Singh answered |
A and B are False : The idea behind Prim’s algorithm is to construct a spanning tree - means all vertices must be connected but here vertices are disconnected C. False. Prim's is a greedy algorithm and At every step, it considers all the edges that connect the two sets, and picks the minimum weight edge from these edges. In this option weight of AB<AD so must be picked up first. D.TRUE. It represents a possible order in which the edges would be added to construct the minimum spanning tree. Prim’s algorithm is also a Greedy algorithm. It starts with an empty spanning tree. The idea is to maintain two sets of vertices. The first set contains the vertices already included in the MST, the other set contains the vertices not yet included. At every step, it considers all the edges that connect the two sets, and picks the minimum weight edge from these edges. After picking the edge, it moves the other endpoint of the edge to the set containing MST.
Consider the graph in figure: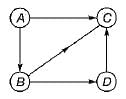 Which of the following is a valid topological sorting?
Which of the following is a valid topological sorting?- a)A B C D
- b)B A C D
- c)B A D C
- d)A B D C
Correct answer is option 'D'. Can you explain this answer?
Consider the graph in figure:
Which of the following is a valid topological sorting?
a)
A B C D
b)
B A C D
c)
B A D C
d)
A B D C
|
|
Janani Joshi answered |
In topological sorting we have to list out all the nodes in such a way that whenever there is an edge connecting i and j, i should precede j in the listing, For some graphs, this is not at all possible, for some this can be done in more than one way.
What is the time complexity of Huffman Coding?- a)O(N)
- b)O(NlogN)
- c)O(N(logN)^2)
- d)O(N^2)
Correct answer is option 'B'. Can you explain this answer?
What is the time complexity of Huffman Coding?
a)
O(N)
b)
O(NlogN)
c)
O(N(logN)^2)
d)
O(N^2)
|
|
Sanya Agarwal answered |
O(nlogn) where n is the number of unique characters. If there are n nodes, extractMin() is called 2*(n – 1) times. extractMin() takes O(logn) time as it calles minHeapify(). So, overall complexity is O(nlogn). See here for more details of the algorithm.
Consider the undirected graph below: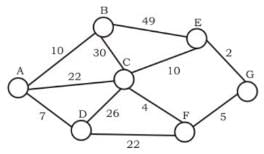
Q.
Using Prim's algorithm to construct a minimum spanning tree starting with node A, which one of the following sequences of edges represents a possible order in which the edges would be added to construct the minimum spanning tree?- a)(E, G), (C, F), (F, G), (A, D), (A, B), (A, C)
- b)(A, D), (A, B), (A, C), (C, F), (G, E), (F, G)
- c)(A, B), (A, D), (D, F), (F, G), (G, E), (F, C)
- d)(A, D), (A, B), (D, F), (F, C), (F, G), (G, E)
Correct answer is option 'D'. Can you explain this answer?
Consider the undirected graph below:
Q.
Using Prim's algorithm to construct a minimum spanning tree starting with node A, which one of the following sequences of edges represents a possible order in which the edges would be added to construct the minimum spanning tree?
a)
(E, G), (C, F), (F, G), (A, D), (A, B), (A, C)
b)
(A, D), (A, B), (A, C), (C, F), (G, E), (F, G)
c)
(A, B), (A, D), (D, F), (F, G), (G, E), (F, C)
d)
(A, D), (A, B), (D, F), (F, C), (F, G), (G, E)
|
|
Diya Chauhan answered |
A and B are False : The idea behind Prim’s algorithm is to construct a spanning tree - means all vertices must be connected but here vertices are disconnected C. False. Prim's is a greedy algorithm and At every step, it considers all the edges that connect the two sets, and picks the minimum weight edge from these edges. In this option weight of AB<AD so must be picked up first. D.TRUE. It represents a possible order in which the edges would be added to construct the minimum spanning tree. Prim’s algorithm is also a Greedy algorithm. It starts with an empty spanning tree. The idea is to maintain two sets of vertices. The first set contains the vertices already included in the MST, the other set contains the vertices not yet included. At every step, it considers all the edges that connect the two sets, and picks the minimum weight edge from these edges. After picking the edge, it moves the other endpoint of the edge to the set containing MST.
Consider the polynominal p(x) = a0 + a1x + a2x2 + a3x3, where 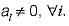 The minimum number of multiplications needed to evaluate p on an input x is
The minimum number of multiplications needed to evaluate p on an input x is - a)3
- b)4
- c)6
- d)9
Correct answer is option 'A'. Can you explain this answer?
Consider the polynominal p(x) = a0 + a1x + a2x2 + a3x3, where The minimum number of multiplications needed to evaluate p on an input x is
The minimum number of multiplications needed to evaluate p on an input x is a)
3
b)
4
c)
6
d)
9
|
|
Nitya Choudhury answered |
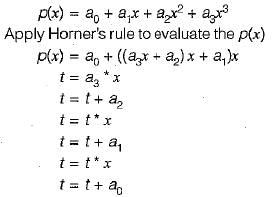
So, 3 minimum number of multiplications needed to evaluate p on an input x.
Consider the directed graph shown in the figure below. There are multiple shortest paths between vertices S and T. Which one will be reported by Dijstra?s shortest path algorithm? Assume that, in any iteration, the shortest path to a vertex v is updated only when a strictly shorter path to v is discovered.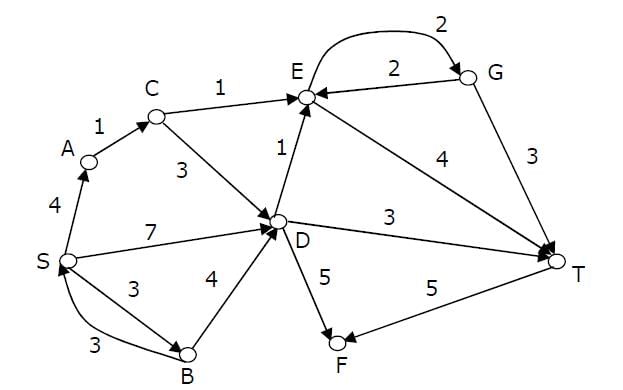
- a)SDT
- b)SBDT
- c)SACDT
- d)SACET
Correct answer is option 'D'. Can you explain this answer?
Consider the directed graph shown in the figure below. There are multiple shortest paths between vertices S and T. Which one will be reported by Dijstra?s shortest path algorithm? Assume that, in any iteration, the shortest path to a vertex v is updated only when a strictly shorter path to v is discovered.
a)
SDT
b)
SBDT
c)
SACDT
d)
SACET
|
|
Sanya Agarwal answered |
See Dijkstra’s shortest path algorithm When the algorithm reaches vertex 'C', the distance values of 'D' and 'E' would be 7 and 6 respectively. So the next picked vertex would be 'E'
In the following table, the left column contains the names of standard graph algorithms and the right column contains the time complexities of the algorithms. Match each algorithm with its time complexity.
- a)1-C, 2-A, 3-B, 4-D
- b)1-B, 2-D, 3-C, 4-A
- c)1-C, 2-D, 3-A, 4-B
- d)1-B, 2-A, 3-C, 4-D
Correct answer is option 'A'. Can you explain this answer?
In the following table, the left column contains the names of standard graph algorithms and the right column contains the time complexities of the algorithms. Match each algorithm with its time complexity.
a)
1-C, 2-A, 3-B, 4-D
b)
1-B, 2-D, 3-C, 4-A
c)
1-C, 2-D, 3-A, 4-B
d)
1-B, 2-A, 3-C, 4-D
|
|
Akanksha Chauhan answered |
Bellman-Ford algorithm: O{nm)
Kruskal’s algorithm : O(mlog n)
Floyd-Warshall algorithm: O(n3)
Kruskal’s algorithm : O(mlog n)
Floyd-Warshall algorithm: O(n3)
Topological sorting : O(n + m)
Chapter doubts & questions for Greedy Techniques - Algorithms 2025 is part of Computer Science Engineering (CSE) exam preparation. The chapters have been prepared according to the Computer Science Engineering (CSE) exam syllabus. The Chapter doubts & questions, notes, tests & MCQs are made for Computer Science Engineering (CSE) 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises, MCQs and online tests here.
Chapter doubts & questions of Greedy Techniques - Algorithms in English & Hindi are available as part of Computer Science Engineering (CSE) exam.
Download more important topics, notes, lectures and mock test series for Computer Science Engineering (CSE) Exam by signing up for free.
Algorithms
81 videos|113 docs|34 tests
|
|
© EduRev
|
Education Revolution
|



|









Signup to see your scores
go up
within 7 days!
within 7 days!
Takes less than 10 seconds to signup