









All Exams >
Computer Science Engineering (CSE) >
Database Management System (DBMS) >
All Questions
All questions of SQL for Computer Science Engineering (CSE) Exam
Which of the following command is used to delete a table in SQL?- a)delete
- b)truncate
- c)remove
- d)drop
Correct answer is option 'D'. Can you explain this answer?
Which of the following command is used to delete a table in SQL?
a)
delete
b)
truncate
c)
remove
d)
drop
|
|
Ravi Singh answered |
drop is used to delete a table completely

Which of the following statements is correct with respect to entity integrity?- a)Entity integrity constraints specify that primary key values can be composite. .
- b)Entity, integrity constraints are specified on individual relations.
- c)Entity integrity constraints are specified between weak entities.
- d)When entity integrity rules are enforced, a tuple in one relation that refers to another relation must refer to an existing tuple.
Correct answer is option 'B'. Can you explain this answer?
Which of the following statements is correct with respect to entity integrity?
a)
Entity integrity constraints specify that primary key values can be composite. .
b)
Entity, integrity constraints are specified on individual relations.
c)
Entity integrity constraints are specified between weak entities.
d)
When entity integrity rules are enforced, a tuple in one relation that refers to another relation must refer to an existing tuple.
|
|
Ashutosh Mukherjee answered |
According to entity integrity primary key of relation should not contain null values.
SQL subqueries that can occur wherever a value is permitted provided the subquery gives only one tuple with a single attribute are called _________- a)Exact Subqueries
- b)Vector Subqueries
- c)Positive Subqueries
- d)Scalar Subqueries
Correct answer is option 'D'. Can you explain this answer?
SQL subqueries that can occur wherever a value is permitted provided the subquery gives only one tuple with a single attribute are called _________
a)
Exact Subqueries
b)
Vector Subqueries
c)
Positive Subqueries
d)
Scalar Subqueries
|
|
Gitanjali Mishra answered |
Scalar Subqueries
Scalar subqueries are subqueries in SQL that can occur wherever a value is permitted, provided the subquery gives only one tuple with a single attribute. These subqueries return a single value, rather than a table or set of rows.
Usage
Scalar subqueries are commonly used in SQL queries to perform calculations, comparisons, or filtering based on a single value returned from a subquery. They can be used in various clauses of a SQL statement, such as SELECT, WHERE, HAVING, and ORDER BY.
Examples
Here are a few examples to illustrate the usage of scalar subqueries:
1. SELECT statement:
```sql
SELECT column1, (SELECT MAX(column2) FROM table2) AS max_value
FROM table1;
```
In this example, the scalar subquery `(SELECT MAX(column2) FROM table2)` returns the maximum value from `column2` in `table2` as a single value. This value is then aliased as `max_value` in the outer query.
2. WHERE clause:
```sql
SELECT column1, column2
FROM table1
WHERE column2 = (SELECT MAX(column2) FROM table2);
```
In this example, the scalar subquery `(SELECT MAX(column2) FROM table2)` is used in the WHERE clause to filter rows from `table1` where `column2` matches the maximum value from `table2`.
3. HAVING clause:
```sql
SELECT column1, AVG(column2) AS avg_value
FROM table1
GROUP BY column1
HAVING AVG(column2) > (SELECT AVG(column2) FROM table1);
```
In this example, the scalar subquery `(SELECT AVG(column2) FROM table1)` is used in the HAVING clause to filter groups of rows based on the average value of `column2`. Only groups with an average value greater than the overall average will be included in the result.
Conclusion
Scalar subqueries are powerful tools in SQL for performing calculations, comparisons, and filtering based on single values returned from subqueries. They can be used in various parts of a SQL statement to enhance query flexibility and functionality.
Scalar subqueries are subqueries in SQL that can occur wherever a value is permitted, provided the subquery gives only one tuple with a single attribute. These subqueries return a single value, rather than a table or set of rows.
Usage
Scalar subqueries are commonly used in SQL queries to perform calculations, comparisons, or filtering based on a single value returned from a subquery. They can be used in various clauses of a SQL statement, such as SELECT, WHERE, HAVING, and ORDER BY.
Examples
Here are a few examples to illustrate the usage of scalar subqueries:
1. SELECT statement:
```sql
SELECT column1, (SELECT MAX(column2) FROM table2) AS max_value
FROM table1;
```
In this example, the scalar subquery `(SELECT MAX(column2) FROM table2)` returns the maximum value from `column2` in `table2` as a single value. This value is then aliased as `max_value` in the outer query.
2. WHERE clause:
```sql
SELECT column1, column2
FROM table1
WHERE column2 = (SELECT MAX(column2) FROM table2);
```
In this example, the scalar subquery `(SELECT MAX(column2) FROM table2)` is used in the WHERE clause to filter rows from `table1` where `column2` matches the maximum value from `table2`.
3. HAVING clause:
```sql
SELECT column1, AVG(column2) AS avg_value
FROM table1
GROUP BY column1
HAVING AVG(column2) > (SELECT AVG(column2) FROM table1);
```
In this example, the scalar subquery `(SELECT AVG(column2) FROM table1)` is used in the HAVING clause to filter groups of rows based on the average value of `column2`. Only groups with an average value greater than the overall average will be included in the result.
Conclusion
Scalar subqueries are powerful tools in SQL for performing calculations, comparisons, and filtering based on single values returned from subqueries. They can be used in various parts of a SQL statement to enhance query flexibility and functionality.
Choose the correct option regarding the following queryWITH max_marks (VALUE) AS
(SELECT MAX(marks)
FROM student)
SELECT studentID
FROM student,max_marks
WHERE student.marks = max_marks.value;- a)The query is syntactically wrong
- b)The query gives the studentID of the student with the maximum marks
- c)The query gives the maximum marks amongst all the students
- d)The query gives all the studentID values except the student with the maximum marks
Correct answer is option 'B'. Can you explain this answer?
Choose the correct option regarding the following query
WITH max_marks (VALUE) AS
(SELECT MAX(marks)
FROM student)
SELECT studentID
FROM student,max_marks
WHERE student.marks = max_marks.value;
(SELECT MAX(marks)
FROM student)
SELECT studentID
FROM student,max_marks
WHERE student.marks = max_marks.value;
a)
The query is syntactically wrong
b)
The query gives the studentID of the student with the maximum marks
c)
The query gives the maximum marks amongst all the students
d)
The query gives all the studentID values except the student with the maximum marks
|
|
Nayanika Sharma answered |
Explanation:
Therefore, the correct option is B.
- The given query first creates a common table expression (CTE) named max_marks which selects the maximum marks from the student table.
- Then it selects the studentID from the student table and max_marks CTE where student's marks are equal to the maximum marks obtained by any student.
- Therefore, the query returns the studentID of the student with the maximum marks.
- Option 'a' is incorrect as the query is syntactically correct.
- Option 'c' is incorrect as the query only selects the studentID, not the maximum marks.
- Option 'd' is incorrect as the query specifically selects the studentID with the maximum marks.
Therefore, the correct option is B.
Which product is returned in a join query have no join condition:- a)Equijoins
- b)Cartesian
- c)Both Equijoins and Cartesian
- d)None of the mentioned
Correct answer is option 'B'. Can you explain this answer?
Which product is returned in a join query have no join condition:
a)
Equijoins
b)
Cartesian
c)
Both Equijoins and Cartesian
d)
None of the mentioned
|
|
Sudhir Patel answered |
A Cartesian coordinate system is a coordinate system that specifies each point uniquely in a plane by a pair of numerical coordinates.
In SQL, relations can contain null values, and comparisons with null values are treated as unknown. Suppose all comparisons with a null value are treated as false. Which of the following pairs is not equivalent?- a)x = 5 AND not(not(x = 5))
- b)x = 5 AND x> 4 and x < 6, where x is an integer
- c)x < 5 AND not (x = 5)
- d)None of the above
Correct answer is option 'C'. Can you explain this answer?
In SQL, relations can contain null values, and comparisons with null values are treated as unknown. Suppose all comparisons with a null value are treated as false. Which of the following pairs is not equivalent?
a)
x = 5 AND not(not(x = 5))
b)
x = 5 AND x> 4 and x < 6, where x is an integer
c)
x < 5 AND not (x = 5)
d)
None of the above
|
|
Parth Sen answered |
For all values smaller than 5, x < 5 will always be true but x = 5 will be false.
Choose the correct statements:- a)Relational algebra and relational calculus are both procedural query languages.
- b)Relational algebra and relational calculus are both non-procedural query languages.
- c)Relational algebra is a procedural query language and relational calculus is a nonprocedural query language.
- d)Relational algebra is a non-procedural query language and relational calculus is a procedural query language.
Correct answer is option 'C'. Can you explain this answer?
Choose the correct statements:
a)
Relational algebra and relational calculus are both procedural query languages.
b)
Relational algebra and relational calculus are both non-procedural query languages.
c)
Relational algebra is a procedural query language and relational calculus is a nonprocedural query language.
d)
Relational algebra is a non-procedural query language and relational calculus is a procedural query language.
|
|
Avantika Menon answered |
Relation algebra is procedural query language while relational calculus is non-procedural query language.
The _________ construct returns true if the argument in the sub-query is void of duplicates- a)not null
- b)not unique
- c)unique
- d)null
Correct answer is option 'C'. Can you explain this answer?
The _________ construct returns true if the argument in the sub-query is void of duplicates
a)
not null
b)
not unique
c)
unique
d)
null
|
|
Aashna Sen answered |
Explanation:
Unique Construct:
- The unique construct is used in SQL to eliminate duplicate values in a sub-query.
- It returns true if the argument in the sub-query is void of duplicates.
Example:
- For example, if we have a table with the following values:
- ID Name
- 1 John
- 2 Jane
- 3 John
- Running a query with the unique construct in a sub-query like this:
- SELECT Name FROM table WHERE ID IN (SELECT DISTINCT ID FROM table)
- The query will return only unique values:
- John
- Jane
Explanation of Option C:
- The correct statement in the question is "The unique construct returns true if the argument in the sub-query is void of duplicates."
- This means that the unique construct will return true when there are no duplicate values present in the sub-query.
Conclusion:
- Therefore, option C "unique" is the correct choice as it accurately describes the behavior of the unique construct in SQL.
Unique Construct:
- The unique construct is used in SQL to eliminate duplicate values in a sub-query.
- It returns true if the argument in the sub-query is void of duplicates.
Example:
- For example, if we have a table with the following values:
- ID Name
- 1 John
- 2 Jane
- 3 John
- Running a query with the unique construct in a sub-query like this:
- SELECT Name FROM table WHERE ID IN (SELECT DISTINCT ID FROM table)
- The query will return only unique values:
- John
- Jane
Explanation of Option C:
- The correct statement in the question is "The unique construct returns true if the argument in the sub-query is void of duplicates."
- This means that the unique construct will return true when there are no duplicate values present in the sub-query.
Conclusion:
- Therefore, option C "unique" is the correct choice as it accurately describes the behavior of the unique construct in SQL.
A relation (from the relational database model) consists of a set of tuples, which implies that- a)Relational model supports multi-valued attributes whose values can be represented in sets.
- b)For any two tuples, the values associated with all of their attributes may be the same.
- c)For any two tuples, the value associated with one or more of their attributes must differ.
- d)All tuples in a particular relation may have different attributes.
Correct answer is option 'C'. Can you explain this answer?
A relation (from the relational database model) consists of a set of tuples, which implies that
a)
Relational model supports multi-valued attributes whose values can be represented in sets.
b)
For any two tuples, the values associated with all of their attributes may be the same.
c)
For any two tuples, the value associated with one or more of their attributes must differ.
d)
All tuples in a particular relation may have different attributes.
|
|
Baishali Dasgupta answered |
Explanation:
Relational database model is based on the concept of relations or tables. A relation consists of a set of tuples, where each tuple represents a single entity or object in the real world. Each tuple has a set of attributes or fields, which represent the properties or characteristics of that entity. The values of these attributes are stored in the corresponding columns of the table.
Let us now understand the given options one by one:
a) Relational model supports multi-valued attributes whose values can be represented in sets.
This statement is incorrect. Relational model does not support multi-valued attributes. Each attribute in a relation can have only a single value. However, we can represent multiple values of an attribute by creating a separate table and establishing a relationship between the two tables.
b) For any two tuples, the values associated with all of their attributes may be the same.
This statement is also incorrect. In a relation, each tuple represents a unique entity, and therefore, the values associated with all of their attributes cannot be the same. There must be at least one attribute whose value differs between the two tuples.
c) For any two tuples, the value associated with one or more of their attributes must differ.
This statement is correct. As explained above, each tuple in a relation represents a unique entity, and therefore, the values associated with all of their attributes cannot be the same. There must be at least one attribute whose value differs between the two tuples.
d) All tuples in a particular relation may have different attributes.
This statement is also incorrect. In a relation, all tuples must have the same set of attributes, although some attributes may have null values in some tuples.
Therefore, the correct answer is option 'C', which states that for any two tuples, the value associated with one or more of their attributes must differ.
Relational database model is based on the concept of relations or tables. A relation consists of a set of tuples, where each tuple represents a single entity or object in the real world. Each tuple has a set of attributes or fields, which represent the properties or characteristics of that entity. The values of these attributes are stored in the corresponding columns of the table.
Let us now understand the given options one by one:
a) Relational model supports multi-valued attributes whose values can be represented in sets.
This statement is incorrect. Relational model does not support multi-valued attributes. Each attribute in a relation can have only a single value. However, we can represent multiple values of an attribute by creating a separate table and establishing a relationship between the two tables.
b) For any two tuples, the values associated with all of their attributes may be the same.
This statement is also incorrect. In a relation, each tuple represents a unique entity, and therefore, the values associated with all of their attributes cannot be the same. There must be at least one attribute whose value differs between the two tuples.
c) For any two tuples, the value associated with one or more of their attributes must differ.
This statement is correct. As explained above, each tuple in a relation represents a unique entity, and therefore, the values associated with all of their attributes cannot be the same. There must be at least one attribute whose value differs between the two tuples.
d) All tuples in a particular relation may have different attributes.
This statement is also incorrect. In a relation, all tuples must have the same set of attributes, although some attributes may have null values in some tuples.
Therefore, the correct answer is option 'C', which states that for any two tuples, the value associated with one or more of their attributes must differ.
Which of the following is not a characteristic of a good database design?- a)Data integrity
- b)Data redundancy
- c)Scalability
- d)Efficiency
Correct answer is option 'B'. Can you explain this answer?
Which of the following is not a characteristic of a good database design?
a)
Data integrity
b)
Data redundancy
c)
Scalability
d)
Efficiency
|
|
Anisha Chavan answered |
Understanding Database Design Characteristics
In the context of database design, several characteristics help ensure a robust and efficient system. Among these, data integrity, scalability, and efficiency are essential, while data redundancy is generally considered a flaw.
Key Characteristics of Good Database Design
Why Data Redundancy is Not a Characteristic
Data redundancy refers to the unnecessary duplication of data within a database. While some level of redundancy can be beneficial for backup purposes, excessive redundancy can lead to several issues:
In summary, while data integrity, scalability, and efficiency are hallmarks of good database design, data redundancy is not, as it compromises the overall effectiveness and reliability of the database.
In the context of database design, several characteristics help ensure a robust and efficient system. Among these, data integrity, scalability, and efficiency are essential, while data redundancy is generally considered a flaw.
Key Characteristics of Good Database Design
- Data Integrity: This refers to the accuracy and consistency of data within the database. A well-designed database enforces rules to maintain correct relationships and prevents invalid data entries.
- Scalability: A good database design should accommodate growth. As the volume of data or the number of transactions increases, the database must maintain performance and efficiency without a complete redesign.
- Efficiency: This involves optimizing queries and data storage to ensure quick access and minimal resource usage. Efficient databases can handle operations swiftly, enhancing user experience.
Why Data Redundancy is Not a Characteristic
Data redundancy refers to the unnecessary duplication of data within a database. While some level of redundancy can be beneficial for backup purposes, excessive redundancy can lead to several issues:
- Increased Storage Costs: Duplicating data consumes more storage space, which can be costly and inefficient.
- Data Anomalies: Redundant data can lead to inconsistencies, making it challenging to maintain data integrity. For example, if one instance of duplicated data is updated and another is not, it can cause confusion and errors.
- Complexity: Managing redundant data increases the complexity of the database, making it harder to maintain and query.
In summary, while data integrity, scalability, and efficiency are hallmarks of good database design, data redundancy is not, as it compromises the overall effectiveness and reliability of the database.
Which are the join types in join condition:- a)Cross join
- b)Natural join
- c)Join with USING clause
- d)All of the mentioned
Correct answer is option 'D'. Can you explain this answer?
Which are the join types in join condition:
a)
Cross join
b)
Natural join
c)
Join with USING clause
d)
All of the mentioned
|
|
Niharika Ahuja answered |
Join Types in Join Condition:
There are several types of join conditions that can be used to combine data from multiple tables in a database. Three common types of join conditions are:
1. Cross Join:
A cross join, also known as a Cartesian join, returns the Cartesian product of the two tables involved in the join. In other words, it combines every row from the first table with every row from the second table, resulting in a potentially large result set. The cross join does not require a join condition, so it can be used when there is no common column between the tables.
2. Natural Join:
A natural join is a type of join that combines two or more tables based on their common column names. It automatically matches the columns with the same name from the two tables and returns the rows where the values in those columns are equal. This type of join eliminates the need to specify a join condition explicitly.
3. Join with USING Clause:
A join with the USING clause is another type of join condition that specifies one or more columns that are common between the tables being joined. It is similar to the natural join, but instead of automatically matching all columns with the same name, it only matches the columns specified in the USING clause. This allows for more control over the join condition and can be useful when there are columns with the same name but different data types.
All of the mentioned:
The correct answer is option 'D' - All of the mentioned. This means that all three join types mentioned above (cross join, natural join, join with USING clause) are valid join conditions that can be used in SQL queries to combine data from multiple tables.
These join types provide different ways to combine data based on the requirements of the query. The choice of join type depends on factors such as the relationship between the tables, the columns to be matched, and the desired result set. By understanding and utilizing these different join types, database developers can efficiently retrieve and combine data from multiple tables.
There are several types of join conditions that can be used to combine data from multiple tables in a database. Three common types of join conditions are:
1. Cross Join:
A cross join, also known as a Cartesian join, returns the Cartesian product of the two tables involved in the join. In other words, it combines every row from the first table with every row from the second table, resulting in a potentially large result set. The cross join does not require a join condition, so it can be used when there is no common column between the tables.
2. Natural Join:
A natural join is a type of join that combines two or more tables based on their common column names. It automatically matches the columns with the same name from the two tables and returns the rows where the values in those columns are equal. This type of join eliminates the need to specify a join condition explicitly.
3. Join with USING Clause:
A join with the USING clause is another type of join condition that specifies one or more columns that are common between the tables being joined. It is similar to the natural join, but instead of automatically matching all columns with the same name, it only matches the columns specified in the USING clause. This allows for more control over the join condition and can be useful when there are columns with the same name but different data types.
All of the mentioned:
The correct answer is option 'D' - All of the mentioned. This means that all three join types mentioned above (cross join, natural join, join with USING clause) are valid join conditions that can be used in SQL queries to combine data from multiple tables.
These join types provide different ways to combine data based on the requirements of the query. The choice of join type depends on factors such as the relationship between the tables, the columns to be matched, and the desired result set. By understanding and utilizing these different join types, database developers can efficiently retrieve and combine data from multiple tables.
In SQL, which data type is best suited for storing large texts such as articles or comments?- a)TEXT
- b)VARCHAR
- c)CHAR
- d)BLOB
Correct answer is option 'A'. Can you explain this answer?
In SQL, which data type is best suited for storing large texts such as articles or comments?
a)
TEXT
b)
VARCHAR
c)
CHAR
d)
BLOB
|
|
Shalini Chopra answered |
Introduction
When it comes to storing large texts such as articles or comments in SQL databases, choosing the right data type is crucial for efficient data handling and retrieval. The best option for this purpose is the TEXT data type.
Why TEXT is the Best Choice
- Capacity: The TEXT data type can store up to 65,535 characters, making it ideal for lengthy entries like articles or comments. In contrast, VARCHAR is limited to 65,535 bytes, which can be restrictive if using multi-byte character sets.
- Flexibility: TEXT allows for variable-length storage, meaning it only uses as much space as needed for the actual content. This efficiency is advantageous when dealing with varying lengths of text.
- Performance: Although TEXT may not be as fast as VARCHAR in certain scenarios, the performance implications are often negligible for large text data. TEXT is optimized for handling larger volumes of data, ensuring that operations remain efficient.
- Indexing Limitations: While VARCHAR can be indexed more effectively, TEXT is still suitable for full-text searches, which are essential for applications involving large texts.
Other Data Types Considered
- VARCHAR: Generally used for shorter strings, VARCHAR can become cumbersome when dealing with large texts since it may require explicit length management.
- CHAR: Best for fixed-length strings, CHAR is not suitable for large texts due to its rigid size and potential for wasted space.
- BLOB: Primarily used for binary data, BLOB is inappropriate for textual content as it does not support direct text manipulation.
Conclusion
In summary, the TEXT data type is the most suitable choice for storing large texts in SQL databases due to its capacity, flexibility, and performance advantages. By using TEXT, developers can ensure efficient handling of extensive content like articles and comments.
When it comes to storing large texts such as articles or comments in SQL databases, choosing the right data type is crucial for efficient data handling and retrieval. The best option for this purpose is the TEXT data type.
Why TEXT is the Best Choice
- Capacity: The TEXT data type can store up to 65,535 characters, making it ideal for lengthy entries like articles or comments. In contrast, VARCHAR is limited to 65,535 bytes, which can be restrictive if using multi-byte character sets.
- Flexibility: TEXT allows for variable-length storage, meaning it only uses as much space as needed for the actual content. This efficiency is advantageous when dealing with varying lengths of text.
- Performance: Although TEXT may not be as fast as VARCHAR in certain scenarios, the performance implications are often negligible for large text data. TEXT is optimized for handling larger volumes of data, ensuring that operations remain efficient.
- Indexing Limitations: While VARCHAR can be indexed more effectively, TEXT is still suitable for full-text searches, which are essential for applications involving large texts.
Other Data Types Considered
- VARCHAR: Generally used for shorter strings, VARCHAR can become cumbersome when dealing with large texts since it may require explicit length management.
- CHAR: Best for fixed-length strings, CHAR is not suitable for large texts due to its rigid size and potential for wasted space.
- BLOB: Primarily used for binary data, BLOB is inappropriate for textual content as it does not support direct text manipulation.
Conclusion
In summary, the TEXT data type is the most suitable choice for storing large texts in SQL databases due to its capacity, flexibility, and performance advantages. By using TEXT, developers can ensure efficient handling of extensive content like articles and comments.
The SQL expression :
SELECT distinct 7.branch_name
FROM branch T, branch S
WHERE T.assets >S.assets and S.branch_city = "PONDICHERRY”
Finds the names of- a)All branches that have greater assets than any branch located in PONDICHERRY.
- b)All branches that have greater assets than all branches located in PONDICHERRY.
- c)The branch that have greater assetin PONDICHERRY.
- d)Any branches that have greater asset than any branch located in PONDICHERRY.
Correct answer is option 'A'. Can you explain this answer?
The SQL expression :
SELECT distinct 7.branch_name
FROM branch T, branch S
WHERE T.assets >S.assets and S.branch_city = "PONDICHERRY”
Finds the names of
SELECT distinct 7.branch_name
FROM branch T, branch S
WHERE T.assets >S.assets and S.branch_city = "PONDICHERRY”
Finds the names of
a)
All branches that have greater assets than any branch located in PONDICHERRY.
b)
All branches that have greater assets than all branches located in PONDICHERRY.
c)
The branch that have greater assetin PONDICHERRY.
d)
Any branches that have greater asset than any branch located in PONDICHERRY.
|
|
Aravind Sengupta answered |
The condition T. assets > S. assets and S. branch_city = “PONDICHERRY” checks for the all those branch-name who have greater assets than any branch located in Pondicherry. The keyword distinct removes the duplicacy of branch_name satisfy the given condition.
If a set is a collection of values given by the select clause, The ______ connective tests for set membership- a)within
- b)include
- c)under
- d)in
Correct answer is option 'D'. Can you explain this answer?
If a set is a collection of values given by the select clause, The ______ connective tests for set membership
a)
within
b)
include
c)
under
d)
in
|
|
Sudhir Patel answered |
The in connective is used to test for the membership in a set, where the set is a collection of values given by the select clause.
Which join refers to join records from the write table that have no matching key in the left table are include in the result set:- a)Left outer join
- b)Right outer join
- c)Full outer join
- d)Half outer join
Correct answer is option 'B'. Can you explain this answer?
Which join refers to join records from the write table that have no matching key in the left table are include in the result set:
a)
Left outer join
b)
Right outer join
c)
Full outer join
d)
Half outer join
|
|
Sankar Sarkar answered |
Right Outer Join Explanation:
The right outer join, also known as a right join, includes all the records from the right table (write table) and only the matching records from the left table. If there is no match found in the left table, NULL values are filled in for the columns from the left table.
Key Points:
- The right outer join is used to join records from the write table that have no matching key in the left table.
- All rows from the right table will be included in the result set, even if there are no matching rows in the left table.
- If there is no match found in the left table, NULL values are filled in for the columns from the left table.
- This type of join helps in identifying records that exist in the write table but do not have corresponding entries in the left table.
In summary, the right outer join is a useful tool when you want to include all records from the write table, regardless of whether there is a matching key in the left table. It helps in analyzing data discrepancies and identifying missing data in relational databases.
Consider the following relation schema pertaining to a students database:Student (rollno, name, address)
Enroll (rollno, courseno, coursename)where the primary keys are shown underlined. The number of tuples in the Student and Enroll tables are 120 and 8 respectively. What are the maximum and minimum number of tuples that can be present in (Student * Enroll), where '*' denotes natural join ?- a)8, 0
- b)120, 8
- c)960, 8
- d)960, 120
Correct answer is option 'A'. Can you explain this answer?
Consider the following relation schema pertaining to a students database:
Student (rollno, name, address)
Enroll (rollno, courseno, coursename)
Enroll (rollno, courseno, coursename)
where the primary keys are shown underlined. The number of tuples in the Student and Enroll tables are 120 and 8 respectively. What are the maximum and minimum number of tuples that can be present in (Student * Enroll), where '*' denotes natural join ?
a)
8, 0
b)
120, 8
c)
960, 8
d)
960, 120
|
|
Nishanth Roy answered |
The result of the natural join is the set of all combinations of tuples in R and S that are equal on their common attribute names. What is the maximum possible number of tuples? The result of natural join becomes equal to the Cartesian product when there are no common attributes. The given tables have a common attribute, so the result of natural join cannot have more than the number of tuples in larger table.
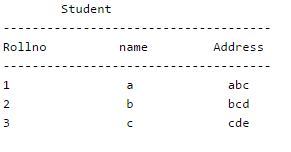

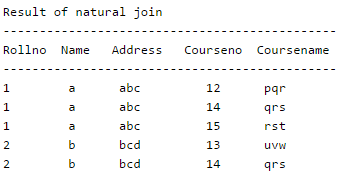
What is the maximum possible number of tuples? It might be possible that there is no rollnumber common. In that case, the number of tupples would be 0.
In SQL, like condition allows you to use wild card characters to perform matching. Which of the following is a valid wild card character?- a)_
- b)$
- c)%
- d)More than one of the above
Correct answer is option 'D'. Can you explain this answer?
In SQL, like condition allows you to use wild card characters to perform matching. Which of the following is a valid wild card character?
a)
_
b)
$
c)
%
d)
More than one of the above

|
Gate Gurus answered |
Key Points
The commonly used wildcard characters in SQL LIKE:
The commonly used wildcard characters in SQL LIKE:
- %: Matches zero, one, or more characters.
- _: Matches a single character (any letter, number, or symbol).
Examples:
- SELECT * FROM customers WHERE name LIKE '%en%'; - This query will find all customer names that contain the letters "en" anywhere in the name (e.g., "John", "Steven", "Weekend").
- SELECT * FROM products WHERE code LIKE 'PR%'; - This query will find all product codes that start with "PR" followed by any characters (e.g., "PR123", "PR-ABC").
- SELECT * FROM users WHERE username LIKE 'user_'; - This query will find all usernames that start with "user_" followed by a single character (e.g., "user_a", "user_1").
Which of the following statements are TRUE about an SQL query?P : An SQL query can contain a HAVING clause even if it does not have a GROUP BY clause
Q : An SQL query can contain a HAVING clause only if it has a GROUP BY clause
R : All attributes used in the GROUP BY clause must appear in the SELECT clause
S : Not all attributes used in the GROUP BY clause need to appear in the SELECT clause- a)P and R
- b)P and S
- c)Q and R
- d)Q and S
Correct answer is option 'C'. Can you explain this answer?
Which of the following statements are TRUE about an SQL query?
P : An SQL query can contain a HAVING clause even if it does not have a GROUP BY clause
Q : An SQL query can contain a HAVING clause only if it has a GROUP BY clause
R : All attributes used in the GROUP BY clause must appear in the SELECT clause
S : Not all attributes used in the GROUP BY clause need to appear in the SELECT clause
Q : An SQL query can contain a HAVING clause only if it has a GROUP BY clause
R : All attributes used in the GROUP BY clause must appear in the SELECT clause
S : Not all attributes used in the GROUP BY clause need to appear in the SELECT clause
a)
P and R
b)
P and S
c)
Q and R
d)
Q and S
|
|
Vaishnavi Yadav answered |
According to standard SQL answer should be C. Refer If we talk about different SQL implementations like MySQL, then option B is also right. But in question they seem to be talking about standard SQL not about implementation. For example below is a P is correct in most of the implementations. HAVING clause can also be used with aggregate function. If we use a HAVING clause without a GROUP BY clause, the HAVING condition applies to all rows that satisfy the search condition. In other words, all rows that satisfy the search condition make up a single group. See this for more details. S is correct . To verify S, try following queries in SQL.
CREATE TABLE temp
(
id INT,
name VARCHAR(100)
);
INSERT INTO temp VALUES (1, "abc"); INSERT INTO temp VALUES (2, "abc"); INSERT INTO temp VALUES (3, "bcd"); INSERT INTO temp VALUES (4, "cde");
(
id INT,
name VARCHAR(100)
);
INSERT INTO temp VALUES (1, "abc"); INSERT INTO temp VALUES (2, "abc"); INSERT INTO temp VALUES (3, "bcd"); INSERT INTO temp VALUES (4, "cde");
SELECT Count(*)
FROM temp
GROUP BY name;
FROM temp
GROUP BY name;
Output:
count(*)
--------
2
1
1
--------
2
1
1
Which of the following operations is not part of the five basic set operations in relational algebra?- a)Union
- b)Division
- c)Cartesian Product
- d)Set Difference
Correct answer is option 'B'. Can you explain this answer?
Which of the following operations is not part of the five basic set operations in relational algebra?
a)
Union
b)
Division
c)
Cartesian Product
d)
Set Difference
|
|
Rishabh Sharma answered |
Five primitive operators of Codd’s algebra are the selection, the projection the Cartesian product, the set union and the set difference.
Consider the set of relations given below and the SQL query that follows:
Students: (Roll_number, Name, date_of_birth)
Courses: (Course_number, Course_name, Instructor)
Grades: (RolL_number, Course_number, Grade)
SELECT DISTINCT Name
FROM Students, Courses, Grades
WHERE Students. RolLnumber = Grades.
RolLnumber
ANDCourse.lnstructor = Korth
AND Courses.Course_number =. Grades. Course_number AND Grades.Grade = A
Which of the following sets is computed by the above query?- a)Names of students who have got an A grade in all courses taught by Korth.
- b)Names of students who have got an A grade in all courses.
- c)Names of students who have got an A grade in at least one of the courses taught by Korth.
- d)None of the above.
Correct answer is option 'C'. Can you explain this answer?
Consider the set of relations given below and the SQL query that follows:
Students: (Roll_number, Name, date_of_birth)
Courses: (Course_number, Course_name, Instructor)
Grades: (RolL_number, Course_number, Grade)
SELECT DISTINCT Name
FROM Students, Courses, Grades
WHERE Students. RolLnumber = Grades.
RolLnumber
ANDCourse.lnstructor = Korth
AND Courses.Course_number =. Grades. Course_number AND Grades.Grade = A
Which of the following sets is computed by the above query?
Students: (Roll_number, Name, date_of_birth)
Courses: (Course_number, Course_name, Instructor)
Grades: (RolL_number, Course_number, Grade)
SELECT DISTINCT Name
FROM Students, Courses, Grades
WHERE Students. RolLnumber = Grades.
RolLnumber
ANDCourse.lnstructor = Korth
AND Courses.Course_number =. Grades. Course_number AND Grades.Grade = A
Which of the following sets is computed by the above query?
a)
Names of students who have got an A grade in all courses taught by Korth.
b)
Names of students who have got an A grade in all courses.
c)
Names of students who have got an A grade in at least one of the courses taught by Korth.
d)
None of the above.
|
|
Rishabh Pillai answered |
Explanation:
The given SQL query selects the distinct names of students who have received an A grade in at least one course taught by Korth. Let's break down the query and understand it step by step.
1. FROM Students, Courses, Grades
- This clause specifies the tables from which we are fetching the data: Students, Courses, and Grades.
2. WHERE Students.Roll_number = Grades.Roll_number
- This condition joins the Students and Grades tables based on the Roll_number attribute. It ensures that we only consider the records where the Roll_number matches in both tables.
3. AND Courses.Instructor = 'Korth'
- This condition further filters the joined result by only considering the records where the Instructor attribute of the Courses table is equal to 'Korth'.
4. AND Courses.Course_number = Grades.Course_number
- This condition ensures that we only consider the records where the Course_number matches in both the Courses and Grades tables.
5. AND Grades.Grade = 'A'
- This condition further filters the result by only considering the records where the Grade attribute of the Grades table is equal to 'A'.
6. SELECT DISTINCT Name
- Finally, we select the distinct names from the result obtained after applying the above conditions.
Conclusion:
The query retrieves the distinct names of students who have received an A grade in at least one course taught by Korth. Therefore, option C is the correct answer: "Names of students who have got an A grade in at least one of the courses taught by Korth."
The given SQL query selects the distinct names of students who have received an A grade in at least one course taught by Korth. Let's break down the query and understand it step by step.
1. FROM Students, Courses, Grades
- This clause specifies the tables from which we are fetching the data: Students, Courses, and Grades.
2. WHERE Students.Roll_number = Grades.Roll_number
- This condition joins the Students and Grades tables based on the Roll_number attribute. It ensures that we only consider the records where the Roll_number matches in both tables.
3. AND Courses.Instructor = 'Korth'
- This condition further filters the joined result by only considering the records where the Instructor attribute of the Courses table is equal to 'Korth'.
4. AND Courses.Course_number = Grades.Course_number
- This condition ensures that we only consider the records where the Course_number matches in both the Courses and Grades tables.
5. AND Grades.Grade = 'A'
- This condition further filters the result by only considering the records where the Grade attribute of the Grades table is equal to 'A'.
6. SELECT DISTINCT Name
- Finally, we select the distinct names from the result obtained after applying the above conditions.
Conclusion:
The query retrieves the distinct names of students who have received an A grade in at least one course taught by Korth. Therefore, option C is the correct answer: "Names of students who have got an A grade in at least one of the courses taught by Korth."
What type of database model organizes data in tables with rows and columns?- a)Hierarchical
- b)Network
- c)Relational
- d)Object-Oriented
Correct answer is option 'C'. Can you explain this answer?
What type of database model organizes data in tables with rows and columns?
a)
Hierarchical
b)
Network
c)
Relational
d)
Object-Oriented

|
Crack Gate answered |
Relational databases organize data in tables with rows and columns.
Given relations R(w, x) and S(y, z), the result of
SELECT DISTINCT w,x
FROM R, S
Is guaranteed to be same as R, if- a)R has no duplicates and S is non-empty
- b)R and S have no duplicates
- c)S has no duplicates and R is non-empty
- d)R and S have the same number of tuples
Correct answer is option 'A'. Can you explain this answer?
Given relations R(w, x) and S(y, z), the result of
SELECT DISTINCT w,x
FROM R, S
Is guaranteed to be same as R, if
SELECT DISTINCT w,x
FROM R, S
Is guaranteed to be same as R, if
a)
R has no duplicates and S is non-empty
b)
R and S have no duplicates
c)
S has no duplicates and R is non-empty
d)
R and S have the same number of tuples
|
|
Preethi Iyer answered |
The given query
SELECT DISTINCT W, X
FROM R, S
Is guaranteed to be same as R, if R has no duplicates and ‘S’ is non-empty.
Since, if R is having a duplicates, then the tuples selected by SELECT operation of the R and the given query will not be same also if ‘S’ is empty then the given query outputs null.
SELECT DISTINCT W, X
FROM R, S
Is guaranteed to be same as R, if R has no duplicates and ‘S’ is non-empty.
Since, if R is having a duplicates, then the tuples selected by SELECT operation of the R and the given query will not be same also if ‘S’ is empty then the given query outputs null.
SQL allows tuples in relations, and correspondingly defines the multiplicity of tuples in the result of joins. Which one of the following queries always gives the same answer as the nested query shown below:select * from R where a in (select S.a from S)- a)select R.* from R, S where R.a=S.a (D)
- b)select distinct R.* from R,S where R.a=S.a
- c)select R.* from R,(select distinct a from S) as S1 where R.a=S1.a
- d)select R.* from R,S where R.a=S.a and is unique R
Correct answer is option 'C'. Can you explain this answer?
SQL allows tuples in relations, and correspondingly defines the multiplicity of tuples in the result of joins. Which one of the following queries always gives the same answer as the nested query shown below:
select * from R where a in (select S.a from S)
a)
select R.* from R, S where R.a=S.a (D)
b)
select distinct R.* from R,S where R.a=S.a
c)
select R.* from R,(select distinct a from S) as S1 where R.a=S1.a
d)
select R.* from R,S where R.a=S.a and is unique R
|
|
Sounak Joshi answered |
The solution of this question lies in the data set(tuples) of Relations R and S we define. If we miss some case then we may get wrong answer. Let's say, Relation R(BCA) with attributes B, C and A contains the following tuples.
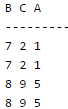
And Relation S(AMN) with attributes A, M, and N contains the following tuples.
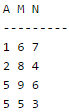
Now ,the original Query will give result as: "select * from R where a in (select S.a from S) " - The query asks to display every tuple of Relation R where R.a is present in the complete set S.a.
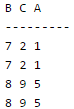
Option A query will result in : "select R.* from R, S where R.a=S.a"
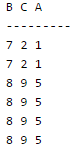
Option B query will result in : " select distinct R.* from R,S where R.a=S.a"

----------------------------------------------------------------------------------------------------------- Option C query will result in : "select R.* from R,(select distinct a from S) as S1 where R.a=S1.a" B C A --------- 7 2 1 7 2 1 8 9 5 8 9 5 ----------------------------------------------------------------------------------------------------------- Option D query will result in : NULL set "select R.* from R,S where R.a=S.a and is unique R" ---------------------------------------------------------------------------------------------------------- Hence option C query matches the original result set. Note : As mentioned earlier, we should take those data sets which can show us the difference in different queries. Suppose in R if you don't put identical tuples then you will get wrong answers. (Try this yourself, this is left as an exercise for you).
Select operation in SQL is equivalent to- a)the selection operation in relational algebra
- b)the selection operation in relational algebra, except that select in SQL retains duplicates
- c)the projection operation in relational algebra
- d)the projection operation in relational algebra, except that select in SQL retains duplicates
Correct answer is option 'D'. Can you explain this answer?
Select operation in SQL is equivalent to
a)
the selection operation in relational algebra
b)
the selection operation in relational algebra, except that select in SQL retains duplicates
c)
the projection operation in relational algebra
d)
the projection operation in relational algebra, except that select in SQL retains duplicates
|
|
Aniket Kulkarni answered |
Select operation is equivalent to the projection operation in relational algebra, except that select in SQL retains duplicates and on the contrary projection removes the duplicates.
State true or false: We can use Subqueries inside the from clause- a)True
- b)False
Correct answer is option 'A'. Can you explain this answer?
State true or false: We can use Subqueries inside the from clause
a)
True
b)
False
|
|
Aashna Sen answered |
Using Subqueries in the FROM Clause
- True: We can use subqueries inside the FROM clause in SQL.
Explanation:
- Subqueries: Subqueries are queries that are nested inside another query. They can be used in various parts of a SQL query, including the FROM clause.
- FROM Clause: The FROM clause is used to specify the tables or subqueries from which data will be retrieved in the main query.
- Using Subqueries in FROM Clause: When we use a subquery in the FROM clause, the result of the subquery is treated as a temporary table, and the main query can then join, filter, or perform other operations on this temporary table.
- Example:
- SELECT * FROM (SELECT column1, column2 FROM table1) AS subquery_table;
- In this example, the subquery (SELECT column1, column2 FROM table1) is used in the FROM clause to create a temporary table called subquery_table.
- Benefits: Using subqueries in the FROM clause can help simplify complex queries, improve readability, and make it easier to break down a query into smaller, more manageable parts.
Overall, using subqueries in the FROM clause is a powerful feature in SQL that allows for greater flexibility and control in querying databases.
_______ symbol is used to see every column of a table.- a)/
- b)_ _
- c)*
- d)!
Correct answer is option 'C'. Can you explain this answer?
_______ symbol is used to see every column of a table.
a)
/
b)
_ _
c)
*
d)
!
|
|
Akshita Choudhury answered |
Explanation:
Symbol for Viewing Every Column in a Table:
- In SQL, the asterisk symbol (*) is used to represent all columns in a table.
- When you use the asterisk symbol in the SELECT statement, it retrieves all columns from the specified table.
Example:
- For example, if you have a table called "employees" with columns such as "id", "name", "department", and "salary", you can use the following query to select all columns:
sql
SELECT * FROM employees;
- This query will return all columns for every row in the "employees" table.
Benefits of Using the Asterisk Symbol:
- Using the asterisk symbol (*) is convenient when you want to retrieve all columns from a table without specifying each column individually.
- It saves time and effort, especially when dealing with tables that have a large number of columns.
Limitations:
- While using the asterisk symbol is convenient, it is important to note that it may not be the most efficient way to retrieve data, especially in large databases.
- Retrieving unnecessary columns can impact the performance of your queries and increase network traffic.
Conclusion:
- In summary, the asterisk symbol (*) is used to view every column of a table in SQL queries. It provides a quick and easy way to retrieve all columns from a table, but it is important to consider the potential drawbacks in terms of performance and efficiency.
Symbol for Viewing Every Column in a Table:
- In SQL, the asterisk symbol (*) is used to represent all columns in a table.
- When you use the asterisk symbol in the SELECT statement, it retrieves all columns from the specified table.
Example:
- For example, if you have a table called "employees" with columns such as "id", "name", "department", and "salary", you can use the following query to select all columns:
sql
SELECT * FROM employees;
- This query will return all columns for every row in the "employees" table.
Benefits of Using the Asterisk Symbol:
- Using the asterisk symbol (*) is convenient when you want to retrieve all columns from a table without specifying each column individually.
- It saves time and effort, especially when dealing with tables that have a large number of columns.
Limitations:
- While using the asterisk symbol is convenient, it is important to note that it may not be the most efficient way to retrieve data, especially in large databases.
- Retrieving unnecessary columns can impact the performance of your queries and increase network traffic.
Conclusion:
- In summary, the asterisk symbol (*) is used to view every column of a table in SQL queries. It provides a quick and easy way to retrieve all columns from a table, but it is important to consider the potential drawbacks in terms of performance and efficiency.
What is the difference between the DROP and TRUNCATE commands in SQL?- a)DROP deletes the table, TRUNCATE deletes only the table data
- b)TRUNCATE deletes the table, DROP deletes only the table data
- c)No difference
- d)Both commands modify table data
Correct answer is option 'A'. Can you explain this answer?
What is the difference between the DROP and TRUNCATE commands in SQL?
a)
DROP deletes the table, TRUNCATE deletes only the table data
b)
TRUNCATE deletes the table, DROP deletes only the table data
c)
No difference
d)
Both commands modify table data

|
Machine Experts answered |
DROP deletes the entire table, while TRUNCATE removes only its data but keeps the table structure.
What is the result of the following query?SELECT studname
FROM college
WHERE marks > SOME (SELECT marks
FROM student
WHERE SECTION = 'c');- a)The query gives all the studnames for which marks are greater than all the students in section c
- b)The query gives all the studnames for which the marks are greater than at least on student in section c
- c)The query gives all the studnames for which the marks are less than all the students in section c
- d)The query is syntactically incorrect
Correct answer is option 'B'. Can you explain this answer?
What is the result of the following query?
SELECT studname
FROM college
WHERE marks > SOME (SELECT marks
FROM student
WHERE SECTION = 'c');
FROM college
WHERE marks > SOME (SELECT marks
FROM student
WHERE SECTION = 'c');
a)
The query gives all the studnames for which marks are greater than all the students in section c
b)
The query gives all the studnames for which the marks are greater than at least on student in section c
c)
The query gives all the studnames for which the marks are less than all the students in section c
d)
The query is syntactically incorrect
|
|
Sudhir Patel answered |
The “some” comparison is used to check for at least one condition. The > symbol is used to test whether the marks are greater than the right hand side or not.
Employee salary should not be greater than Rs. 12,000. This is- a)Integrity constraint
- b)Referential constraint
- c)Over-defined constraint
- d)None of the above
Correct answer is option 'A'. Can you explain this answer?
Employee salary should not be greater than Rs. 12,000. This is
a)
Integrity constraint
b)
Referential constraint
c)
Over-defined constraint
d)
None of the above
|
|
Sagar Saha answered |
Understanding Integrity Constraints
Integrity constraints are rules that ensure the accuracy and consistency of data within a database. They play a crucial role in maintaining the quality of information stored. In this context, the statement "Employee salary should not be greater than Rs. 12,000" represents an integrity constraint for the following reasons:
Types of Constraints Explained
- Integrity Constraint: This constraint ensures that data adheres to specific rules. In this case, the rule is that employee salaries must not exceed Rs. 12,000. This maintains data validity and prevents erroneous data entries.
- Referential Constraint: This type of constraint ensures that relationships between tables remain consistent. For example, ensuring that an employee ID in one table corresponds to an existing ID in another.
- Over-defined Constraint: This term typically refers to constraints that are unnecessarily complicated or redundant. It does not apply in this context, as the salary limit is a straightforward requirement.
- None of the Above: This option suggests that the statement does not fit any of the provided categories, which is incorrect since it clearly aligns with integrity constraints.
Conclusion
The statement about employee salaries being capped at Rs. 12,000 is indeed an integrity constraint. It ensures that the data entered into the system remains valid and within permissible limits, thereby protecting the integrity of the database.
Integrity constraints are rules that ensure the accuracy and consistency of data within a database. They play a crucial role in maintaining the quality of information stored. In this context, the statement "Employee salary should not be greater than Rs. 12,000" represents an integrity constraint for the following reasons:
Types of Constraints Explained
- Integrity Constraint: This constraint ensures that data adheres to specific rules. In this case, the rule is that employee salaries must not exceed Rs. 12,000. This maintains data validity and prevents erroneous data entries.
- Referential Constraint: This type of constraint ensures that relationships between tables remain consistent. For example, ensuring that an employee ID in one table corresponds to an existing ID in another.
- Over-defined Constraint: This term typically refers to constraints that are unnecessarily complicated or redundant. It does not apply in this context, as the salary limit is a straightforward requirement.
- None of the Above: This option suggests that the statement does not fit any of the provided categories, which is incorrect since it clearly aligns with integrity constraints.
Conclusion
The statement about employee salaries being capped at Rs. 12,000 is indeed an integrity constraint. It ensures that the data entered into the system remains valid and within permissible limits, thereby protecting the integrity of the database.
How many join types in join condition:- a)2
- b)3
- c)4
- d)5
Correct answer is option 'D'. Can you explain this answer?
How many join types in join condition:
a)
2
b)
3
c)
4
d)
5
|
|
Sudhir Patel answered |
INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN, EQUIJOIN.
Which is a join condition contains an equality operator:- a)Equijoins
- b)Cartesian
- c)Both Equijoins and Cartesian
- d)None of the mentioned
Correct answer is option 'A'. Can you explain this answer?
Which is a join condition contains an equality operator:
a)
Equijoins
b)
Cartesian
c)
Both Equijoins and Cartesian
d)
None of the mentioned
|
|
Sudhir Patel answered |
An equi-join is a specific type of comparator-based join, that uses only equality comparisons in the join-predicate.
Let R(a, b, c) and S(d, e, f) be two relations in which d is the foreign key of S that refers to the primary key of R. Consider the following four operations R and S
1. Insert into R
2. Insert into S
3. Delete from R
4. Delete from S
Which of the following is true about the referential integrity constraint above?- a)None of 1, 2, 3 or 4 can cause its violation
- b)All of 1, 2, 3 and 4 can cause its violation
- c)Both 1 and 4 can cause its violation
- d)Both 2 and 3 can cause its violation
Correct answer is option 'D'. Can you explain this answer?
Let R(a, b, c) and S(d, e, f) be two relations in which d is the foreign key of S that refers to the primary key of R. Consider the following four operations R and S
1. Insert into R
2. Insert into S
3. Delete from R
4. Delete from S
Which of the following is true about the referential integrity constraint above?
1. Insert into R
2. Insert into S
3. Delete from R
4. Delete from S
Which of the following is true about the referential integrity constraint above?
a)
None of 1, 2, 3 or 4 can cause its violation
b)
All of 1, 2, 3 and 4 can cause its violation
c)
Both 1 and 4 can cause its violation
d)
Both 2 and 3 can cause its violation
|
|
Keerthana Sarkar answered |
Referential integrity constraint: In relational model, two relation are related to each other over the basis of attributes, Every value of referencing attribute must be null or be available in the referenced attribute.
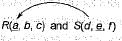
Here d is the foreign key of S that refers to the primary key of R.
1. Insert into R will not cause any violation.
2. Insert into S may cause violation because for each entry in ‘S ’ it must be. in ‘R ’ .
3. Delete from R may cause violation because for the deleted entry in R there may be referenced entry in the reIation S.
4. Delete from S will not cause any violation.
Hence (d) is the correct option.
Here d is the foreign key of S that refers to the primary key of R.
1. Insert into R will not cause any violation.
2. Insert into S may cause violation because for each entry in ‘S ’ it must be. in ‘R ’ .
3. Delete from R may cause violation because for the deleted entry in R there may be referenced entry in the reIation S.
4. Delete from S will not cause any violation.
Hence (d) is the correct option.
What is a correlated sub-query?- a)An independent query that uses the correlation name of another independent query.
- b)A sub-query that uses the correlation name of an outer query
- c)A sub-query that substitutes the names of the outer query
- d)A sub-query that does not depend on its outer query’s correlation names
Correct answer is option 'B'. Can you explain this answer?
What is a correlated sub-query?
a)
An independent query that uses the correlation name of another independent query.
b)
A sub-query that uses the correlation name of an outer query
c)
A sub-query that substitutes the names of the outer query
d)
A sub-query that does not depend on its outer query’s correlation names
|
|
Meghana Tiwari answered |
B) A sub-query that uses the correlation name of an outer query
Which view that contains more than one table in the top-level FROM clause of the SELECT statement:- a)Join view
- b)Datable join view
- c)Updatable join view
- d)All of the mentioned
Correct answer is option 'C'. Can you explain this answer?
Which view that contains more than one table in the top-level FROM clause of the SELECT statement:
a)
Join view
b)
Datable join view
c)
Updatable join view
d)
All of the mentioned
|
|
Sudhir Patel answered |
The DELETE statement is used to delete rows in a table. The UPDATE statement is used to update existing records in a table. The INSERT INTO statement is used to insert new records in a table.
A_____ is a query that retrieves rows from more than one table or view:- a)Start
- b)End
- c)Join
- d)All of the mentioned
Correct answer is option 'C'. Can you explain this answer?
A_____ is a query that retrieves rows from more than one table or view:
a)
Start
b)
End
c)
Join
d)
All of the mentioned
|
|
Sudhir Patel answered |
An SQL join clause combines records from two or more tables in a database. It creates a set that can be saved as a table or used as it is. A JOIN is a means for combining fields from two tables by using values common to each.
The employee information in a company is stored in the relation. Assume name is the primary key:
Employee: (name, sex, salary, deptName)
Consider the SQL query;
SELECT deptName
FROM Employee
WHERE sex = M
GROUP By deptName
HAVING avg(salary) > (SELECT avg(salary)
FROM Employee)
It returns the names of the departments in which the average salary. - a)Is more than the average salary in the company.
- b)Of the male employees is more than the average salary of all the male employees in the company.
- c)Of the male employees is more than the average salary of the employees in the same department.
- d)Of the male employees is more than the average salary in the company.
Correct answer is option 'D'. Can you explain this answer?
The employee information in a company is stored in the relation. Assume name is the primary key:
Employee: (name, sex, salary, deptName)
Consider the SQL query;
SELECT deptName
FROM Employee
WHERE sex = M
GROUP By deptName
HAVING avg(salary) > (SELECT avg(salary)
FROM Employee)
It returns the names of the departments in which the average salary.
Employee: (name, sex, salary, deptName)
Consider the SQL query;
SELECT deptName
FROM Employee
WHERE sex = M
GROUP By deptName
HAVING avg(salary) > (SELECT avg(salary)
FROM Employee)
It returns the names of the departments in which the average salary.
a)
Is more than the average salary in the company.
b)
Of the male employees is more than the average salary of all the male employees in the company.
c)
Of the male employees is more than the average salary of the employees in the same department.
d)
Of the male employees is more than the average salary in the company.
|
|
Tarun Saini answered |
The given query first calculates the average salary from the relation Employee, then it selects the department name where employees who have average salary more than the average salary of the company.
Which operation are allowed in a join view:- a)UPDATE
- b)INSERT
- c)DELETE
- d)All of the mentioned
Correct answer is option 'D'. Can you explain this answer?
Which operation are allowed in a join view:
a)
UPDATE
b)
INSERT
c)
DELETE
d)
All of the mentioned
|
|
Sudhir Patel answered |
The DELETE statement is used to delete rows in a table. The UPDATE statement is used to update existing records in a table. The INSERT INTO statement is used to insert new records in a table.
Branch-scheme = (Branch - name, assets, branch- city)
Customer-scheme = (Customer-name, street, customer- city)
Deposit-scheme = (Branch-name, account-number, customer-name, balance)
Borrow-scheme = (Branch-name, loan-number, customer-name, amount)
Client-scheme = (Customer-name, banker-name)
Which of the following queries finds the clients of banker Agassi and the city they live in?


- a)1 and 3
- b)2 and 3
- c)1 and 4
- d)None of these
Correct answer is option 'A'. Can you explain this answer?
Branch-scheme = (Branch - name, assets, branch- city)
Customer-scheme = (Customer-name, street, customer- city)
Deposit-scheme = (Branch-name, account-number, customer-name, balance)
Borrow-scheme = (Branch-name, loan-number, customer-name, amount)
Client-scheme = (Customer-name, banker-name)
Which of the following queries finds the clients of banker Agassi and the city they live in?
Customer-scheme = (Customer-name, street, customer- city)
Deposit-scheme = (Branch-name, account-number, customer-name, balance)
Borrow-scheme = (Branch-name, loan-number, customer-name, amount)
Client-scheme = (Customer-name, banker-name)
Which of the following queries finds the clients of banker Agassi and the city they live in?
a)
1 and 3
b)
2 and 3
c)
1 and 4
d)
None of these
|
|
Anand Chatterjee answered |
Clients of Bankers Agassi can be obtained by using the relation client_scheme while the corresponding customer_city can be obtained -using customer_scheme.
Hence cross product of client and customer must be taken. This can be achieved in two ways.
(i) First taking the Bankers Agassi clients and then checking their name in customer relation and projecting their customer city.
(ii) First taking all the customers and matching them in customer_scheme, then finding out the customers who have the Agassi as the Banker, finally projecting the customer_city of the respective customers.
Hence cross product of client and customer must be taken. This can be achieved in two ways.
(i) First taking the Bankers Agassi clients and then checking their name in customer relation and projecting their customer city.
(ii) First taking all the customers and matching them in customer_scheme, then finding out the customers who have the Agassi as the Banker, finally projecting the customer_city of the respective customers.
Which SQL aggregate function is used to retrieve minimum value?- a)max
- b)min
- c)avg
- d)None of the above
Correct answer is option 'B'. Can you explain this answer?
Which SQL aggregate function is used to retrieve minimum value?
a)
max
b)
min
c)
avg
d)
None of the above
|
|
Machine Experts answered |
Aggregate functions are functions that take a collection (a set or multiset) of values as input and return a single value. SQL offers five built-in aggregate functions:
- Average: avg
- Minimum: min
- Maximum: max
- Total: sum
- Count: count
Which SQL command is used to create a new table in a database?- a)CREATE
- b)ALTER
- c)DROP
- d)TRUNCATE
Correct answer is option 'A'. Can you explain this answer?
Which SQL command is used to create a new table in a database?
a)
CREATE
b)
ALTER
c)
DROP
d)
TRUNCATE
|
|
Machine Experts answered |
The CREATE command is used to create a new table in a database.
Branch-scheme = (Branch - name, assets, branch- city)
Customer-scheme = (Customer-name, street, customer- city)
Deposit-scheme = (Branch-name, account-number, customer-name, balance)
Borrow-scheme = (Branch-name, loan-number, customer-name, amount)
Client-scheme = (Customer-name, banker-name)
Which of the following Domain relational calculus finds all customers who have a loan amount of over 1200?- a)
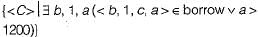
- b)
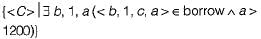
- c)
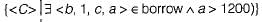
- d)
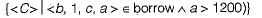
Correct answer is option 'B'. Can you explain this answer?
Branch-scheme = (Branch - name, assets, branch- city)
Customer-scheme = (Customer-name, street, customer- city)
Deposit-scheme = (Branch-name, account-number, customer-name, balance)
Borrow-scheme = (Branch-name, loan-number, customer-name, amount)
Client-scheme = (Customer-name, banker-name)
Which of the following Domain relational calculus finds all customers who have a loan amount of over 1200?
Customer-scheme = (Customer-name, street, customer- city)
Deposit-scheme = (Branch-name, account-number, customer-name, balance)
Borrow-scheme = (Branch-name, loan-number, customer-name, amount)
Client-scheme = (Customer-name, banker-name)
Which of the following Domain relational calculus finds all customers who have a loan amount of over 1200?
a)
b)
c)
d)
|
|
Sankar Sarkar answered |
All customers who have a lone amount of over 1200
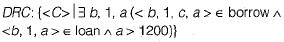
In SQL, what is the purpose of the TRUNCATE command?- a)Deletes specific rows from a table
- b)Removes all rows from a table
- c)Changes table structure
- d)Creates a new table
Correct answer is option 'B'. Can you explain this answer?
In SQL, what is the purpose of the TRUNCATE command?
a)
Deletes specific rows from a table
b)
Removes all rows from a table
c)
Changes table structure
d)
Creates a new table
|
|
Gate Gurus answered |
The TRUNCATE command is used to remove all rows from a table.
In SQL, what is the purpose of the WHERE clause in a DELETE statement?- a)Specifies which database to use
- b)Specifies which table to delete from
- c)Specifies which records to delete
- d)Specifies how to order the records
Correct answer is option 'C'. Can you explain this answer?
In SQL, what is the purpose of the WHERE clause in a DELETE statement?
a)
Specifies which database to use
b)
Specifies which table to delete from
c)
Specifies which records to delete
d)
Specifies how to order the records
|
|
Gate Gurus answered |
The WHERE clause in a DELETE statement specifies which records should be deleted.
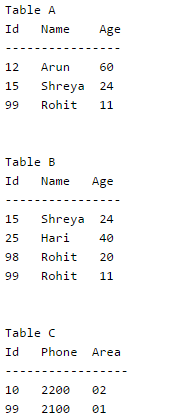 Consider the above tables A, B and C. How many tuples does the result of the following SQL query contains?
Consider the above tables A, B and C. How many tuples does the result of the following SQL query contains?
- a)4
- b)3
- c)0
- d)1
Correct answer is option 'B'. Can you explain this answer?
Consider the above tables A, B and C. How many tuples does the result of the following SQL query contains?
a)
4
b)
3
c)
0
d)
1
|
|
Pranab Sharma answered |
The meaning of “ALL” is the A.Age should be greater than all the values returned by the subquery. There is no entry with name “arun” in table B. So the subquery will return NULL. If a subquery returns NULL, then the condition becomes true for all rows of A (See this for details). So all rows of table A are selected.
Consider the relation "enrolled(student, course)" in which (student, course) is the primary key, and the relation "paid(student, amount)" where student is the primary key. Assume no null values and no foreign keys or integrity constraints. Given the following four queries: Q. Which one of the following statements is correct?
Q. Which one of the following statements is correct?- a)All queries return identical row sets for any database
- b)Query2 and Query4 return identical row sets for all databases but there exist databases for which Query1 and Query2 return different row sets.
- c)There exist databases for which Query3 returns strictly fewer rows than Query2
- d)There exist databases for which Query4 will encounter an integrity violation at runtime.
Correct answer is option 'B'. Can you explain this answer?
Consider the relation "enrolled(student, course)" in which (student, course) is the primary key, and the relation "paid(student, amount)" where student is the primary key. Assume no null values and no foreign keys or integrity constraints. Given the following four queries:
Q. Which one of the following statements is correct?
a)
All queries return identical row sets for any database
b)
Query2 and Query4 return identical row sets for all databases but there exist databases for which Query1 and Query2 return different row sets.
c)
There exist databases for which Query3 returns strictly fewer rows than Query2
d)
There exist databases for which Query4 will encounter an integrity violation at runtime.

|
Chandu Chowdary answered |
Query 1 : gives who paid the amount for the course
Query 2 : gives who have paid and also enrolled into the course
Query 3 : it gives same as query 1 and it also gives the duplicate names too....
Query 4 : same as query 2 ...
so the final answer would be ... option B
Query 2 : gives who have paid and also enrolled into the course
Query 3 : it gives same as query 1 and it also gives the duplicate names too....
Query 4 : same as query 2 ...
so the final answer would be ... option B


Join Selectivity of a relation R in a natural join with a relation S is the _____- a)Ratio of the distinct attribute values for attribute A participating in the join to the total number of distinct attributes for the same attribute in R.
- b)Ratio of the non-distinct attribute values for attribute A participating in the join to the total number of distinct values for the same attribute in R.
- c)Ratio of the distinct attribute values for attribute A participating in the join to the total number of non-distinct values for the same attribute in R.
- d)None of the above
Correct answer is option 'A'. Can you explain this answer?
Join Selectivity of a relation R in a natural join with a relation S is the _____
a)
Ratio of the distinct attribute values for attribute A participating in the join to the total number of distinct attributes for the same attribute in R.
b)
Ratio of the non-distinct attribute values for attribute A participating in the join to the total number of distinct values for the same attribute in R.
c)
Ratio of the distinct attribute values for attribute A participating in the join to the total number of non-distinct values for the same attribute in R.
d)
None of the above
|
|
Shubham Sharma answered |
Explanation:
When performing a natural join between two relations, the selectivity of the join refers to the ratio of the distinct attribute values for a particular attribute in the join to the total number of distinct attribute values for the same attribute in one of the relations.
Let's break down the options:
a) Ratio of the distinct attribute values for attribute A participating in the join to the total number of distinct attributes for the same attribute in R.
This option is correct. It correctly describes the selectivity of the relation R in a natural join with relation S.
b) Ratio of the non-distinct attribute values for attribute A participating in the join to the total number of distinct values for the same attribute in R.
This option is not correct. It refers to non-distinct attribute values, which is not what selectivity is measuring.
c) Ratio of the distinct attribute values for attribute A participating in the join to the total number of non-distinct values for the same attribute in R.
This option is not correct. It refers to the total number of non-distinct values, which is not what selectivity is measuring.
d) None of the above.
This option is not correct. Option a is the correct answer.
In summary:
The selectivity of a relation R in a natural join with a relation S is the ratio of the distinct attribute values for attribute A participating in the join to the total number of distinct attributes for the same attribute in R.
When performing a natural join between two relations, the selectivity of the join refers to the ratio of the distinct attribute values for a particular attribute in the join to the total number of distinct attribute values for the same attribute in one of the relations.
Let's break down the options:
a) Ratio of the distinct attribute values for attribute A participating in the join to the total number of distinct attributes for the same attribute in R.
This option is correct. It correctly describes the selectivity of the relation R in a natural join with relation S.
b) Ratio of the non-distinct attribute values for attribute A participating in the join to the total number of distinct values for the same attribute in R.
This option is not correct. It refers to non-distinct attribute values, which is not what selectivity is measuring.
c) Ratio of the distinct attribute values for attribute A participating in the join to the total number of non-distinct values for the same attribute in R.
This option is not correct. It refers to the total number of non-distinct values, which is not what selectivity is measuring.
d) None of the above.
This option is not correct. Option a is the correct answer.
In summary:
The selectivity of a relation R in a natural join with a relation S is the ratio of the distinct attribute values for attribute A participating in the join to the total number of distinct attributes for the same attribute in R.
Given relations r(w, x) and s(y, z), the result of is guaranteed to be same as r, provided
is guaranteed to be same as r, provided- a)r has no duplicates and s is non-empty
- b)r and s have no duplicates
- c)s has no duplicates and r is non-empty
- d)r and s have the same number of tuples
Correct answer is option 'A'. Can you explain this answer?
Given relations r(w, x) and s(y, z), the result of
is guaranteed to be same as r, provided
a)
r has no duplicates and s is non-empty
b)
r and s have no duplicates
c)
s has no duplicates and r is non-empty
d)
r and s have the same number of tuples

|
Anirban Khanna answered |
R has no duplicates and s is non-empty The query selects all attributes of r. Since we have distinct in query, result can be equal to r only if r doesn’t have duplicates. If we do not give any attribute on which we want to join two tables, then the queries like above become equivalent to Cartesian product. Cartisian product of two sets will be empty if any of the two sets is empty. So, s should have atleast one record to get all rows of r.
The ________ comparison checker is used to check “each and every” condition- a)all
- b)and
- c)every
- d)each
Correct answer is option 'A'. Can you explain this answer?
The ________ comparison checker is used to check “each and every” condition
a)
all
b)
and
c)
every
d)
each
|
|
Sudhir Patel answered |
The all comparison checker is used to check “each and every” condition. The “each” and “every” comparison checkers do not exist in SQL.
The ______ construct returns true if a given tuple is present in the subquery.- a)not exists
- b)present
- c)not present
- d)exists
Correct answer is option 'D'. Can you explain this answer?
The ______ construct returns true if a given tuple is present in the subquery.
a)
not exists
b)
present
c)
not present
d)
exists
|
|
Sudhir Patel answered |
The exists construct returns true if a given tuple is present in the subquery. The not exists construct gives true if a given tuple is not present in the subquery.
Chapter doubts & questions for SQL - Database Management System (DBMS) 2025 is part of Computer Science Engineering (CSE) exam preparation. The chapters have been prepared according to the Computer Science Engineering (CSE) exam syllabus. The Chapter doubts & questions, notes, tests & MCQs are made for Computer Science Engineering (CSE) 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises, MCQs and online tests here.
Chapter doubts & questions of SQL - Database Management System (DBMS) in English & Hindi are available as part of Computer Science Engineering (CSE) exam.
Download more important topics, notes, lectures and mock test series for Computer Science Engineering (CSE) Exam by signing up for free.
Database Management System (DBMS)
63 videos|93 docs|37 tests
|
|
© EduRev
|
Education Revolution
|



|









Signup on EduRev and stay on top of your study goals
10M+ students crushing their study goals daily